02 Jan 2011
Di tahun yang baru ini, kami di ArtiVisi juga beralih menggunakan version control baru, yaitu Git.
Menggantikan Subversion yang sudah kita gunakan sejak 2008.
Ada banyak keunggulan Git dibandingkan Subversion, diantaranya:
-
offline operation. Git adalah distributed/decentralized version control system (DVCS), artinya tidak membutuhkan server terpusat untuk bisa bekerja. Keunggulan ini berakibat pada keunggulan berikutnya, yaitu:
-
commit sesuai task, bukan sesuai koneksi internet. Dulu, karena koneksi internet terbatas, programmer commit hanya pada saat ada internet. Akibatnya satu commit berisi perubahan untuk banyak task, tercampur aduk tidak jelas peruntukannya. DVCS memungkinkan programmer untuk commit walaupun tidak ada koneksi internet, dan melakukan sinkronisasi pada saat offline.
-
fitur staging area di Git, memungkinkan kita untuk mengatur isi commit secara detail.
-
fitur rebase untuk mengatur commit. Commit yang teratur akan memudahkan review.
-
branch dan merge yang lebih baik daripada subversion. Karena branch dan merge mudah, maka kita bisa menerapkan berbagai teknik workflow dalam mengelola development.
-
website social coding. Github dan Gitorious merupakan Facebook-nya para programmer. Untuk bisa terlibat di dalamnya, terlebih dulu kita harus bisa Git.
Selain Git, ada juga DVCS lain seperti Mercurial (hg), Bazaar (bzr), dsb. Git dipilih karena :
-
popularitas. Semakin populer, tutorial dan aplikasi pendukung semakin banyak, sehingga semakin nyaman digunakan. Saat ini yang paling populer cuma dua, yaitu git dan hg.
-
local/named branch. Ini fitur penting, tapi entah kenapa tidak ada di core hg. Sepertinya ada di extension, tapi yang jelas merupakan workaround dan bukan didesain sejak awal. Tanpa named branch, pilihan workflow menjadi terbatas.
-
Social coding Git (Github dan Gitorious) jauh lebih superior daripada Mercurial (Bitbucket)
Beberapa faktor di atas adalah alasan kenapa Git yang dipilih.
Baiklah, sekarang saatnya migrasi. Kita akan mengkonversi repository Subversion menjadi repository Git.
Berikut langkah-langkah yang akan kita lakukan:
-
Dump repository Subversion
-
Restore lagi di laptop supaya cepat
-
Buat authorsfile
-
Buat ignore file
-
Clone tanpa metadata
-
Konversi branch
-
Konversi tags
-
Clone hasil konversi menjadi bare repository
Dump repository Subversion
Seperti biasa, sebelum melakukan apapun, lakukan backup dulu. Just in case.
Perintahnya gampang.
svnadmin dump /path/ke/repository | bzip2 -c9 > dump-repository-yyyyMMdd.dmp.bz2
Restore lagi di laptop/PC supaya cepat
Langkah ini optional, kalau kita ingin melakukannya di komputer kita sendiri, bukan di server.
Tapi sebaiknya dilakukan, karena nanti kita akan checkout beberapa kali yang pasti membutuhkan waktu lama jika dilakukan ke server.
Perintah restore gampang.
bzcat dump-repository-yyyyMMdd.dmp.bz2 | svnadmin load /path/ke/repo/svn/di/lokal
Buat authorsfile
Setelah kita memiliki repository Subversion, kita perlu mengambil daftar nama orang-orang yang pernah commit. Ini akan kita butuhkan pada waktu konversi. Nama committer ini diambil dari hasil checkout Subversion. Jadi mari kita checkout dulu.
svn checkout file:///path/ke/repo/svn/di/lokal checkout-project-svn
Karena lokal, harusnya hanya membutuhkan beberapa menit saja.
Setelah dilakukan checkout, kita membutuhkan script untuk mengambil nama committer. Berikut isi scriptnya, simpan saja dengan nama extract-svn-authors.sh
#!/usr/bin/env bash
authors=$(svn log -q | grep -e '^r' | awk 'BEGIN { FS = "|" } ; { print $2 }' | sort | uniq)
for author in ${authors}; do
echo "${author} = NAME <USER@DOMAIN>";
done
Jalankan script tersebut di dalam folder hasil checkout.
cd checkout-project-svn
sh /path/ke/script/extract-svn-authors.sh > nama-committers.txt
Ini akan menghasilkan file nama-committers.txt yang berisi nama committer seperti ini :
endy = NAME <USER@DOMAIN>
Editlah file ini supaya mencerminkan nama dan email yang benar, seperti ini :
endy = Endy Muhardin <endy.muhardin@geemail.com>
Buat ignore file
Dalam mengerjakan project, ada file-file yang ada di folder kerja, tapi tidak kita masukkan ke repository. Misalnya file hasil kompilasi, setting IDE, dan sebagainya. File dan folder hasil generate ini biasanya kita daftarkan di ignore list, supaya tidak ikut dicommit ke repository. Kita perlu mengkonversi format ignore di Subversion (svn property ignore) menjadi format ignore versi Git (yaitu file .gitignore).
Untuk membuatnya, kita clone dulu repository Subversion menjadi repository Git. Ini dilakukan di folder yang berbeda dengan hasil checkout Subversion di langkah sebelumnya.
cd ..
git svn clone --stdlayout -A nama-committers.txt file:///path/ke/repo git-svn-migrasi-project-dengan-metadata
Setelah diclone, konversi ignore list nya.
cd git-svn-migrasi-project-dengan-metadata
git svn show-ignore > .gitignore
Selanjutnya, kita lakukan clone lagi. Kali ini tanpa menyertakan metadata, sehingga hasilnya bersih. Metadata ini digunakan bila kita ingin tetap commit ke repository Subversion, tapi ingin menggunakan Git sebagai frontend.
Perintahnya mirip seperti sebelumnya, kali ini kita tambahkan opsi tanpa metadata.
cd ..
git svn clone --no-metadata --stdlayout -A nama-committers.txt file:///path/ke/repo git-svn-migrasi-project-tanpa-metadata
Ini akan menghasilkan folder git-svn-migrasi-project-tanpa-metadata berisi repository Subversion yang sudah dikonversi menjadi repository Git. Semua langkah selanjutnya akan dilakukan di dalam folder ini.
Setelah selesai, kita masukkan file .gitignore ke repo Git yang baru ini.
cd git-svn-migrasi-project-tanpa-metadata
cp ../git-svn-migrasi-project-dengan-metadata/.gitignore ./
git add .
git commit -m "add ignore list"
Konversi branch
Branch yang ada di Subversion harus kita konversi menjadi branch di Git.
Berikut perintahnya.
git branch -r | grep -v tags | sed -rne 's, *([^@]+)$,\1,p' | while read branch; do echo "git branch $branch $branch"; done | sh
Verifikasi hasilnya dengan perintah ini.
Seharusnya semua branch yang ada di repository Subversion akan terlihat di dalam repository Git ini.
Lakukan perintah berikut untuk mengkonversi tag Subversion menjadi tag Git.
git branch -r | sed -rne 's, *tags/([^@]+)$,\1,p' | while read tag; do echo "git tag $tag 'tags/${tag}^'; git branch -r -d tags/$tag"; done | sh
Verifikasi dengan perintah ini
Pastikan semua tag yang tadinya ada di repository Subversion sudah terdaftar di repository Git.
Clone hasil konversi menjadi bare repository
Setelah nama committer, ignore list, branch, dan tags berhasil kita pindahkan, inilah langkah terakhir. Kita clone sekali lagi menjadi repository bare supaya bisa dishare dengan orang lain. Biasanya repository bare ini kita publish dengan Gitosis, gitweb, atau aplikasi server lainnya.
Perintah ini dilakukan di luar repository Git yang kita gunakan pada langkah sebelumnya.
cd ..
git clone --bare git-svn-migrasi-project-tanpa-metadata nama-project.git
Ini akan menghasilkan satu folder dengan nama nama-project.git berisi repository Git yang siap dishare.
Demikian posting tahun baru. Semoga kita semua lebih sukses di tahun 2011 ini.
06 Jul 2010
Pada waktu kita melakukan requirement gathering, harapan kita adalah agar requirement yang kita dapatkan di fase requirement tidak jauh bergeser dari requirement final setelah project closing. Kalau pergeserannya jauh, akan mengakibatkan waktu dan biaya pengerjaan project menjadi molor dan akibatnya kedua belah pihak akan dirugikan.
Pergeseran requirement ini bisa disebabkan beberapa hal, misalnya :
-
business analyst (BA) kurang pengalaman, sehingga tidak bisa mengidentifikasi varian-varian skenario. Akibatnya terjadi banyak ‘hidden requirement’
-
business analyst kurang teliti, sehingga salah memahami penjelasan user
-
Perubahan bisnis client, sehingga requirementnya juga berubah
-
perbedaan persepsi antara user dan analyst atau programmer
Untuk masalah 1 dan 2, solusinya adalah dengan mengganti BA dengan orang yang lebih berpengalaman. Newbie sebaiknya tidak menjadi BA. Bolehlah magang BA, tapi jangan diandalkan untuk jadi BA utama.
Poin 3 juga biasanya tidak masalah. Client biasanya cukup tahu diri kalau terjadi hal ini, sehingga tidak keberatan dimintai charge tambahan.
Nah untuk poin 4, biasanya sulit dideteksi sampai aplikasi kita deliver. Sering terjadi, usernya OK OK saja pada fase requirement, dan tiba-tiba pada waktu kita deliver aplikasinya, dia langsung bingung karena aplikasinya ‘aneh’.
Agar poin 4 ini tidak terjadi, sebaiknya kita melakukan prototyping. Bagaimana cara melakukan prototyping yang baik?
Prototyping itu idealnya :
-
Murah meriah dan cepat
Dalam 1 hari kita harus bisa menggambar minimal 10 screen.
Begitu usernya selesai ngomong/gambar di papan tulis, screennya juga harus langsung jadi.
Jangan sampai effort untuk prototyping lebih besar dari effort untuk coding.
-
Gampang diubah
Tujuan prototype adalah supaya user bisa merasakan seperti apa aplikasinya nanti.
Kalau dirasakan kurang sesuai, tentunya dia ingin mengubahnya.
Nah, jangan sampai minta geser tombol aja harus nunggu 30 menit.
-
Mirip aslinya.
Kalo ini lebih ke sisi development.
Biar efisien, begitu prototype sign off, kita bisa mulai paralel coding dan bikin user manual.
Kalo prototypenya udah bener2 mirip, bisa langsung discreenshot dan dipasang di user manual.
Jadi begitu aplikasi jadi, user manual juga selesai.
-
Terlihat belum selesai
Ini agak kontradiktif dengan tips #3. Kalau prototype kita sangat mirip aplikasi betulan, client akan memiliki persepsi bahwa aplikasinya sudah hampir selesai. Padahal belum ada coding sama sekali. Oleh karena itu, sangat penting kita tekankan ke client bahwa masih ada jangka waktu yang lama sebelum aplikasi betulannya selesai.
Ada beberapa tools yang bisa digunakan untuk prototyping, yaitu
Untuk project aplikasi desktop, inilah yang biasa kami gunakan di ArtiVisi. Screen dapat dibuat dengan sangat cepat, lengkap dengan behavior standar seperti popup dialog, scroll table, dsb.
Untuk project web, biasanya kita langsung coding di HTML dan Dojo, tentunya tanpa koneksi ke back end.
Sebagai nilai tambah lain, setelah prototype di-approve client, programmer bisa langsung meneruskan coding.
Tools ini berbayar dan dijalankan menggunakan Adobe AIR.
Pencil
Tools ini lumayan bagus, dijalankan sebagai Firefox Add Ons. Sudah ada palette untuk berbagai UI component seperti combo box, text area, dsb. Setelah selesai menggambar, kita bisa langsung mengekspornya menjadi image.
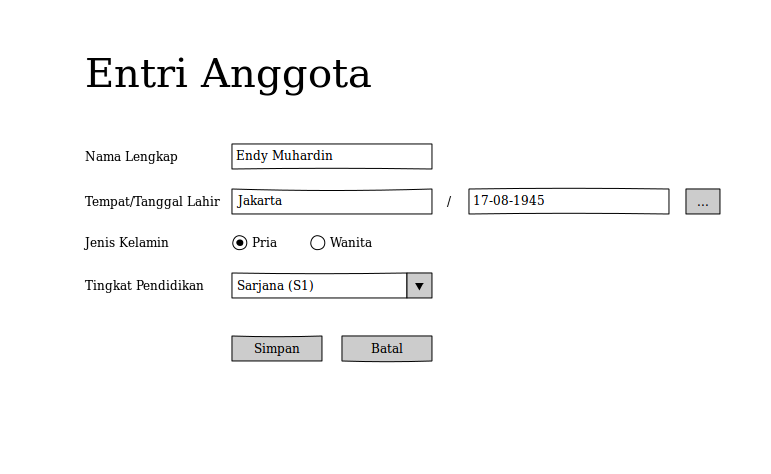
Berikut contoh mockup yang baru saja saya buat menggunakan Pencil.
Ini versi ‘bagus’ yang mirip aslinya.
Supaya client sadar bahwa ini adalah prototype, kita bisa gunakan versi yang coret-coretan.
Source file untuk mockup di atas bisa diunduh di sini.
Demikianlah sedikit tips dan trik. Semoga bermanfaat.
30 Jun 2010
Suatu aplikasi, walaupun sudah go-live di environment production, tetap bisa saja mengalami error dan bug. Bug ini seringkali tidak ditemukan di environment development karena berbagai hal, misalnya variasi data, jumlah data, dan sebagainya.
Langkah pertama ketika kita mengetahui ada bug tentunya adalah melokalisir masalah. Pada kondisi mana saja bug tersebut muncul. Setelah itu, kita dapat memfokuskan pencarian masalah di lokasi tersebut. Ini lebih efisien daripada kita harus menelusuri keseluruhan sistem.
Misalnya kita sudah berhasil melokalisir masalah, yaitu transaksi di bulan tertentu. Langkah selanjutnya adalah memindahkan data production di lokasi tersebut ke environment development. Ini kita lakukan supaya kita bebas bereksperimen dengan data tersebut tanpa khawatir membahayakan data production.
Masalahnya, tools backup database yang tersedia biasanya tidak bisa digunakan untuk mengambil sebagian data. Walaupun bisa (mysqldump menyediakan opsi where untuk membatasi record yang diambil), biasanya terbatas hanya di satu tabel saja. Sedangkan untuk bisa merestore-nya di development, kita butuh semua relasinya.
Sebagai contoh, coba lihat skema berikut.
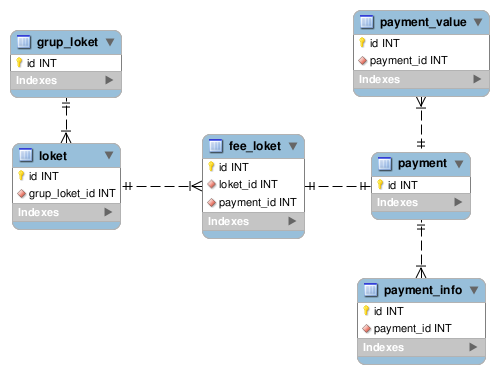
Untuk mengambil data payment, tentunya kita juga harus menarik data lain yang berelasi dengannya, yaitu di tabel grup loket, loket, payment value, payment info dan fee loket. Ini sangat sulit dilakukan, apalagi kalau data payment tersebut jumlahnya ratusan ribu record.
Untunglah ada tools untuk mengatasi masalah ini, namanya Jailer. Dengan menggunakan Jailer, kita dapat menentukan tabel mana yang akan diambil datanya (payment), kriteria pengambilan (bulan tertentu saja), dan relasi mana saja yang ingin kita ambil. Hasilnya adalah satu set data lengkap dengan dependensinya yang bisa kita restore di development.
Persiapan Jailer
Pertama, tentunya kita unduh dulu Jailer di websitenya. Jangan lupa teriakkan, “Hidup Open Source !!!”, karena aplikasi ini tersedia secara gratis berkat gerakan open source.
Setelah berhasil diunduh, extract ke folder tertentu. Jailer tidak menyertakan driver untuk koneksi ke database, sehingga kita harus sediakan sendiri. Karena saya menggunakan MySQL, saya masukkan file mysql-connector.jar ke dalam folder lib. Kita mengikutkan driver database ke folder Jailer karena nantinya folder ini akan kita pack dan upload ke server production.
Jailer ini akan kita jalankan di mesin development yang sudah terisi skema database. Kita akan coba dulu ambil data di development, kalau sudah sukses baru kita jalankan di production.
Ada dua script untuk menjalankan jailer, yaitu jailerGUI dan jailer. jailerGUI digunakan untuk mendesain pengambilan data, sedangkan jailer adalah antarmuka command line untuk menjalankan pengambilan data. Karena kita ingin mendesain proses pengambilannya, kita gunakan jailerGUI.
Berikut adalah tampilan awal Jailer.
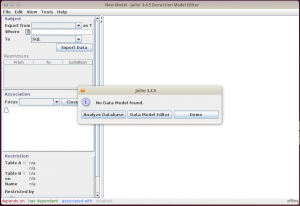
Jailer memberitahu kita bahwa belum ada data model yang bisa dikerjakan, dan menyarankan kita untuk menganalisa database. Klik Analyze Database. Selanjutnya Jailer akan meminta informasi cara koneksi ke database.
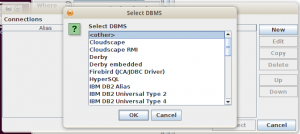
Isikan informasi koneksi database dan driver yang digunakan. Driver yang kita gunakan adalah yang tadi sudah kita copy ke folder lib.
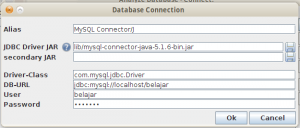
Klik OK untuk menganalisa database.
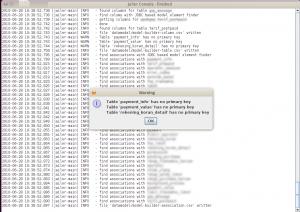
Setelah itu, Jailer akan menghubungi database untuk mengambil informasi. Lognya akan ditampilkan di log output. Jailer akan memberi tahu kita tabel-tabel yang tidak ada primary keynya. Jailer tidak dapat memproses tabel tanpa primary key.
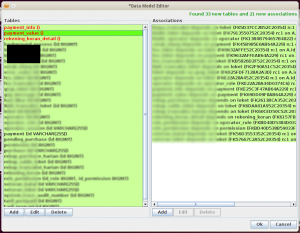
Klik tabel yang berwarna merah, dan definisikan primary keynya. Primary key yang kita definisikan di sini hanya digunakan Jailer, sehingga tidak perlu khawatir skema aslinya akan berubah.
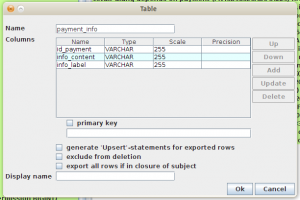
Setelah itu, klik OK. Jailer akan menampilkan screen Extraction Model Editor. Pilih tabel payment, di dropdown subject, karena inilah tabel yang akan kita gunakan sebagai pusat extraction.
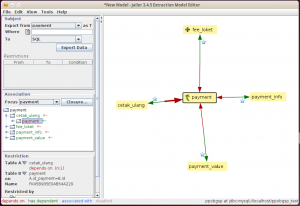
Jailer mendeteksi relasi antar tabel berdasarkan constraint foreign key yang kita pasang di database. Kadangkala ada tabel-tabel yang berelasi, namun tidak ada constraintnya. Entah karena malas mendefinisikan, atau memang sengaja tidak dikaitkan. Kita bisa mendaftarkan relasi tanpa constraint ini dengan membuka lagi Data Model Editor, kemudian klik Add di kotak Association sebelah kanan.

Setelah diklik OK, maka skema relasi di Extraction Model Editor akan berubah sesuai relasi yang ditambahkan. Sama dengan definisi primary key di atas, relasi ini hanya disimpan oleh Jailer dan tidak diaplikasikan ke skema database.
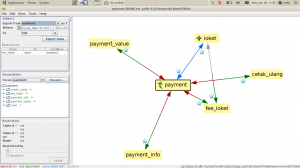
Kita perlu mendefinisikan batasan record payment yang akan diambil, yaitu yang terjadi di bulan Juni 2010. Dalam bentuk SQL, berikut adalah query yang digunakan
select * from payment where date_format(paid_date, '%Y-%m') = '2010-06'
Kita ambil expression setelah where dan pasang di textfield where dalam Extraction Model Editor.
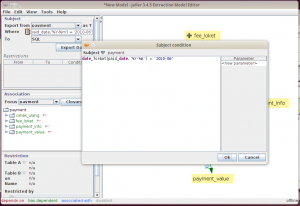
Simpan dulu extraction modelnya.
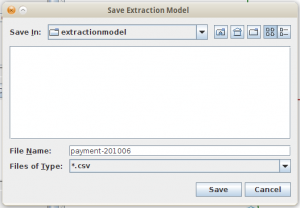
Beri nama yang representatif, misalnya payment-201006. Jailer akan menyimpan extraction model ini dalam format csv. Kalau sudah memahami formatnya, kita bisa membuatnya dengan text editor tanpa GUI (kalau mau).
Setelah tersimpan, kita bisa klik Export Data sehingga memunculkan dialog berikut.
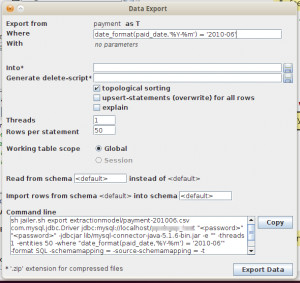
Di screen tersebut kita bisa mengatur konfigurasi pengambilan data. Bagi saya, nilai defaultnya sudah memadai sehingga tidak ada yang diubah.
Di box paling bawah ada command line yang bisa kita copy-paste untuk dijalankan tanpa GUI. Copy saja isinya ke text file untuk digunakan nanti.
Yang harus kita isi di screen ini adalah textfield Into. Ini adalah nama file yang akan menampung script SQL berisi data yang diinginkan. Isi saja dengan nama payment-201006.sql.
Setelah itu, klik Export Data. Jailer akan segera bekerja dan menampilkan hasilnya dalam bentuk tree.
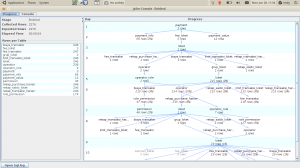
Di situ kita bisa lihat berapa row yang akan diambil dari masing-masing tabel.
Seperti kita lihat, cukup signifikan, yaitu 2000an record. Ini disebabkan karena jailer mengambil record secara rekursif tanpa ada batasan.
Setelah dianalisa, kita hanya ingin mengambil tabel-tabel yang berkaitan langsung, yaitu payment, payment_info, payment_value, dan fee_loket. Sedangkan tabel sisanya dapat diabaikan karena bersifat pelengkap atau master data yang sudah ada di database development.
Dengan melihat ke tree-nya, kita bisa memutus relasi fee_loket ke loket, karena dari situlah semua data lain akan ikut terbawa.
Tutup screennya, dan kembali ke Extraction Model Editor.
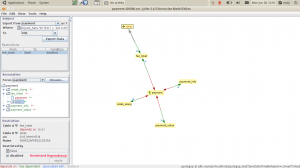
Di kotak Association, expand node yang ingin kita putuskan, yaitu fee loket. Klik relasi loket, dan centang checkbox disabled di pojok kiri bawah. Setelah itu, jalankan lagi Export Data.
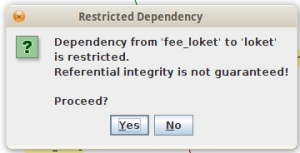
Jailer akan mengingatkan bahwa dengan membatasi dependensi, referential integrity akan rusak, karena relasi foreign key dari fee_loket ke loket akan terputus. Klik saja Yes, karena di database development kita tabel loket sudah terisi lengkap.
Inilah hasilnya
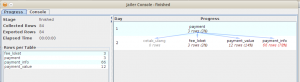
Seperti kita lihat di atas, kita cuma mendapatkan 84 record dan pengambilan data berhenti di tabel fee_loket.
Periksa output payment-201006.sql di folder Jailer untuk memastikan hasilnya sudah benar.
Setelah sukses dijalankan di database development, compress lagi jailer yang sudah dimodifikasi barusan dan upload ke server production. Setibanya di server production, extract, kemudian jalankan script yang tadi kita copy-paste.
Kalau baru pertama kali dijalankan, script ini akan menimbulkan error sebagai berikut :
$ ./export-payment-201006.sh
2010-06-28 14:15:08,114 [main] INFO - Jailer 3.4.5
2010-06-28 14:15:08,117 [main] INFO - added 'lib/mysql-connector-java-5.1.6-bin.jar' to classpath
2010-06-28 14:15:08,119 [main] INFO - exporting 'extractionmodel/payment-201006.csv' to 'payment-201006.sql'
2010-06-28 14:15:08,700 [main] INFO - begin guessing SQL dialect
2010-06-28 14:15:08,711 [main] INFO - end guessing SQL dialect
2010-06-28 14:15:08,718 [main] ERROR - Can't find working tables! Run 'bin/jailer.sh create-ddl' and execute the DDL-script first!
java.lang.RuntimeException: Can't find working tables! Run 'bin/jailer.sh create-ddl' and execute the DDL-script first!
at net.sf.jailer.entitygraph.EntityGraph.create(EntityGraph.java:122)
at net.sf.jailer.Jailer.export(Jailer.java:1142)
at net.sf.jailer.Jailer.jailerMain(Jailer.java:1064)
at net.sf.jailer.Jailer.jailerMain(Jailer.java:989)
at net.sf.jailer.Jailer.main(Jailer.java:967)
Caused by: java.sql.SQLException: "Table 'ppobgsp_test.JAILER_GRAPH' doesn't exist" in statement "Insert into JAILER_GRAPH(id, age) values (2104021762, 1)"
at net.sf.jailer.database.Session.executeUpdate(Session.java:470)
at net.sf.jailer.entitygraph.EntityGraph.create(EntityGraph.java:120)
... 4 more
Error: java.lang.RuntimeException: Can't find working tables! Run 'bin/jailer.sh create-ddl' and execute the DDL-script first!
2010-06-28 14:15:08,724 [main] ERROR - working directory is /opt/downloads/java/tools/test/integration-test/jailer
Ini disebabkan karena Jailer ternyata membuat beberapa tabel di database untuk kebutuhan internalnya. Ini dapat dilihat pada database development kita.
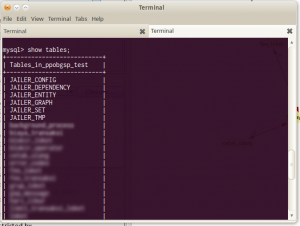
Untuk menggenerate tabel di atas, kita jalankan jailer dengan opsi create-ddl. Ini akan menghasilkan SQL di layar. SQL ini harus kita jalankan di database production supaya tabelnya terbentuk.
$ sh jailer.sh create-ddl
DROP TABLE JAILER_ENTITY;
DROP TABLE JAILER_DEPENDENCY;
DROP TABLE JAILER_SET;
DROP TABLE JAILER_GRAPH;
DROP TABLE JAILER_CONFIG;
DROP TABLE JAILER_TMP;
CREATE TABLE JAILER_CONFIG
(
jversion VARCHAR(20),
jkey VARCHAR(200),
jvalue VARCHAR(200)
) ;
INSERT INTO JAILER_CONFIG(jversion, jkey, jvalue) values('3.4.5', 'magic', '837065098274756382534403654245288');
CREATE TABLE JAILER_GRAPH
(
id INTEGER NOT NULL,
age INTEGER NOT NULL
-- ,CONSTRAINT jlr_pk_graph PRIMARY KEY(id)
) ;
CREATE TABLE JAILER_ENTITY
(
r_entitygraph INTEGER NOT NULL,
PK0 BIGINT , PK1 VARCHAR(255) , PK2 VARCHAR(255) , PK3 INT , PK4 VARCHAR(255) , PK5 BIGINT ,
birthday INTEGER NOT NULL,
type VARCHAR(120) NOT NULL,
PRE_PK0 BIGINT , PRE_PK1 VARCHAR(255) , PRE_PK2 VARCHAR(255) , PRE_PK3 INT , PRE_PK4 VARCHAR(255) , PRE_PK5 BIGINT ,
PRE_TYPE VARCHAR(120),
orig_birthday INTEGER,
association INTEGER
-- , CONSTRAINT jlr_fk_graph_e FOREIGN KEY (r_entitygraph) REFERENCES JAILER_GRAPH(id)
) ;
CREATE INDEX jlr_enty_brthdy ON JAILER_ENTITY (r_entitygraph, birthday, type) ;
CREATE INDEX jlr_enty_upk1 ON JAILER_ENTITY (r_entitygraph , PK0, PK1, PK2, PK3, PK4, PK5, type) ;
CREATE TABLE JAILER_SET
(
set_id INTEGER NOT NULL,
type VARCHAR(120) NOT NULL,
PK0 BIGINT , PK1 VARCHAR(255) , PK2 VARCHAR(255) , PK3 INT , PK4 VARCHAR(255) , PK5 BIGINT
) ;
CREATE INDEX jlr_pk_set1 ON JAILER_SET (set_id , PK0, PK1, PK2, PK3, PK4, PK5, type) ;
CREATE TABLE JAILER_DEPENDENCY
(
r_entitygraph INTEGER NOT NULL,
assoc INTEGER NOT NULL,
depend_id INTEGER NOT NULL,
traversed INTEGER,
from_type VARCHAR(120) NOT NULL,
to_type VARCHAR(120) NOT NULL,
FROM_PK0 BIGINT , FROM_PK1 VARCHAR(255) , FROM_PK2 VARCHAR(255) , FROM_PK3 INT , FROM_PK4 VARCHAR(255) , FROM_PK5 BIGINT ,
TO_PK0 BIGINT , TO_PK1 VARCHAR(255) , TO_PK2 VARCHAR(255) , TO_PK3 INT , TO_PK4 VARCHAR(255) , TO_PK5 BIGINT
-- , CONSTRAINT jlr_fk_graph_d FOREIGN KEY (r_entitygraph) REFERENCES JAILER_GRAPH(id)
) ;
CREATE INDEX jlr_dep_from1 ON JAILER_DEPENDENCY (r_entitygraph, assoc , FROM_PK0, FROM_PK1, FROM_PK2, FROM_PK3, FROM_PK4, FROM_PK5) ;
CREATE INDEX jlr_dep_to1 ON JAILER_DEPENDENCY (r_entitygraph , TO_PK0, TO_PK1, TO_PK2, TO_PK3, TO_PK4, TO_PK5) ;
CREATE TABLE JAILER_TMP
(
c1 INTEGER,
c2 INTEGER
) ;
INSERT INTO JAILER_CONFIG(jversion, jkey, jvalue) values('3.4.5', 'upk', '679547784');
Setelah tabelnya siap, jalankan kembali script yang error di atas. Berikut outputnya.
$ ./export-payment-201006.sh
2010-06-28 14:12:31,175 [main] INFO - Jailer 3.4.5
2010-06-28 14:12:31,190 [main] INFO - added 'lib/mysql-connector-java-5.1.6-bin.jar' to classpath
2010-06-28 14:12:31,191 [main] INFO - exporting 'extractionmodel/payment-201006.csv' to 'payment-201006.sql'
2010-06-28 14:12:32,850 [main] INFO - SQL dialect is MYSQL
2010-06-28 14:12:32,925 [main] INFO - gather statistics after 0 inserted rows...
2010-06-28 14:12:32,966 [main] INFO - reading file 'renew.sql'
2010-06-28 14:12:32,966 [main] INFO - 0 statements (100%)
2010-06-28 14:12:32,967 [main] INFO - successfully read file 'renew.sql'
2010-06-28 14:12:32,977 [main] INFO - exporting payment Where date_format(paid_date,'%Y-%m') = '2010-06'
2010-06-28 14:12:33,028 [main] INFO - day 1, progress: payment
2010-06-28 14:12:33,039 [main] INFO - starting 4 jobs
2010-06-28 14:12:33,040 [main] INFO - gather statistics after 3 inserted rows...
2010-06-28 14:12:33,041 [main] INFO - reading file 'renew.sql'
2010-06-28 14:12:33,042 [main] INFO - 0 statements (100%)
2010-06-28 14:12:33,042 [main] INFO - successfully read file 'renew.sql'
2010-06-28 14:12:33,047 [main] INFO - resolving payment -> payment_info (inverse-FKE25C3F47AB64A229) 1:n on B.id_payment=A.id...
2010-06-28 14:12:33,105 [main] INFO - 66 entities found resolving payment -> payment_info (inverse-FKE25C3F47AB64A229) 1:n on B.id_payment=A.id
2010-06-28 14:12:33,105 [main] INFO - resolving payment -> cetak_ulang (inverse-FK45B985E0AB64A229) 1:n on B.id_payment=A.id...
2010-06-28 14:12:33,126 [main] INFO - 0 entities found resolving payment -> cetak_ulang (inverse-FK45B985E0AB64A229) 1:n on B.id_payment=A.id
2010-06-28 14:12:33,126 [main] INFO - resolving payment -> fee_loket (inverse-FK9632AFFEAB64A229) 1:n on B.id_payment=A.id...
2010-06-28 14:12:33,129 [main] INFO - 3 entities found resolving payment -> fee_loket (inverse-FK9632AFFEAB64A229) 1:n on B.id_payment=A.id
2010-06-28 14:12:33,131 [main] INFO - resolving payment -> payment_value (inverse-FK69DD09F8AB64A229) 1:n on B.id_payment=A.id...
2010-06-28 14:12:33,142 [main] INFO - 12 entities found resolving payment -> payment_value (inverse-FK69DD09F8AB64A229) 1:n on B.id_payment=A.id
2010-06-28 14:12:33,143 [main] INFO - executed 4 jobs
2010-06-28 14:12:33,143 [main] INFO - day 2, progress: payment_info, fee_loket, payment_value
2010-06-28 14:12:33,144 [main] INFO - skip reversal association payment_info -> payment
2010-06-28 14:12:33,144 [main] INFO - skip reversal association fee_loket -> payment
2010-06-28 14:12:33,147 [main] INFO - skip reversal association payment_value -> payment
2010-06-28 14:12:33,147 [main] INFO - starting 1 jobs
2010-06-28 14:12:33,148 [main] INFO - executed 1 jobs
2010-06-28 14:12:33,149 [main] INFO - exported payment Where date_format(paid_date,'%Y-%m') = '2010-06'
2010-06-28 14:12:33,149 [main] INFO - total progress: payment_info, payment, fee_loket, payment_value
2010-06-28 14:12:33,149 [main] INFO - export statistic:
2010-06-28 14:12:33,169 [main] INFO - Exported Rows: 84
2010-06-28 14:12:33,169 [main] INFO - fee_loket 3
2010-06-28 14:12:33,169 [main] INFO - payment 3
2010-06-28 14:12:33,172 [main] INFO - payment_info 66
2010-06-28 14:12:33,172 [main] INFO - payment_value 12
2010-06-28 14:12:33,173 [main] INFO - writing file 'payment-201006.sql'...
2010-06-28 14:12:33,178 [main] INFO - independent tables: payment
2010-06-28 14:12:33,179 [main] INFO - starting 1 jobs
2010-06-28 14:12:33,380 [main] INFO - executed 1 jobs
2010-06-28 14:12:33,380 [main] INFO - independent tables: payment_info, fee_loket, payment_value
2010-06-28 14:12:33,384 [main] INFO - starting 3 jobs
2010-06-28 14:12:33,447 [main] INFO - executed 3 jobs
2010-06-28 14:12:33,447 [main] INFO - cyclic dependencies for:
2010-06-28 14:12:33,447 [main] INFO - starting 0 jobs
2010-06-28 14:12:33,448 [main] INFO - executed 0 jobs
2010-06-28 14:12:33,448 [main] INFO - gather statistics after 84 inserted rows...
2010-06-28 14:12:33,450 [main] INFO - reading file 'renew.sql'
2010-06-28 14:12:33,450 [main] INFO - 0 statements (100%)
2010-06-28 14:12:33,454 [main] INFO - successfully read file 'renew.sql'
2010-06-28 14:12:33,456 [main] INFO - starting 0 jobs
2010-06-28 14:12:33,467 [main] INFO - executed 0 jobs
2010-06-28 14:12:33,486 [main] INFO - file 'payment-201006.sql' written.
Selesai sudah, data yang kita inginkan ada di file payment-201006.sql, siap diunduh dan dijalankan di database development.
Semoga bermanfaat, kalau ada yang kurang jelas, silahkan baca tutorial resminya.
05 May 2010
Setelah aplikasi dicoding dengan benar, biasanya langkah berikutnya adalah tuning performance. Hal ini banyak ditanyakan di berbagai milis pemrograman yang saya ikuti. Agar tidak berkali-kali menulis jawaban yang sama, berikut artikel tentang metodologi saya dalam melakukan tuning performance aplikasi.
0. Miliki tujuan yang jelas
Misalnya :
Mampu menghandle 100 request/detik dengan response time < 2 detik
dengan 1 juta record di database. Bisa jadi pada tahap ini, ternyata keputusannya adalah tidak perlu tuning, karena performance aplikasi yang sekarang sudah memenuhi keinginan.
1. Pastikan aplikasinya berjalan benar
Make it right, then make it fast.
Gak ada gunanya mentuning aplikasi buggy.
Kita juga harus punya perangkat pengetes yang lengkap.
Supaya nanti setelah tuning, bisa dipastikan bahwa tuningnya tidak menimbulkan bug baru.
2. Pasang monitor di aplikasi
Misalnya :
- CPU usage
- Memory usage
- Aktifitas harddisk
- Aktifitas database
Di linux, CPU dan Memory usage bisa dipantau dengan top,
sedangkan aktifitas harddisk dengan iostat.
Di MySQL, aktifitas database bisa dimonitor dengan perintah show processlist.
3. Setelah monitor siap, penyiksaan dimulai
Berikan load yang tinggi ke aplikasi dengan menggunakan tools penyiksaan seperti misalnya JMeter.
Tingkatkan terus loadnya sampai response time tidak lagi memenuhi syarat.
Misalnya, pada 30 request/detik, response time menjadi 10 detik.
4. Cari bottlenecknya
Amati monitor, aspek mana yang overload.
Apakah CPU, I/O, atau memori.
Perhatikan juga aktifitas database untuk mencari penyebabnya.
5. Lakukan tuning
Silahkan dioprek dengan metode trial and error.
Biasanya pada tahap ini saya mencari kolom mana yang perlu diindex,
bagian mana di source code yang perlu diperbaiki,
atau konfigurasi seperti apa yang optimal.
6. Test lagi
Setelah dioprek, jalankan lagi tools penyiksaan.
Kalau langkah no #5 benar, biasanya bottlenecknya akan pindah.
Misalnya, tadinya CPU maxed out 100%, setelah tuning jadi santai 10%,
tapi memory usage jadi 80%.
7. Ulangi langkah #5 dan #6
Ulangi terus tuning dan test sampai aplikasi memenuhi tujuan yang diset di langkah #0.
Inilah pentingnya langkah #0, supaya kita tahu kapan harus berhenti.
Beberapa hal yang harus diingat dalam tuning performance:
-
Tidak ada pil ajaib, masing-masing kasus berbeda. Kadang masalahnya ada di index database, kadang di prosesor, dsb.
-
Jangan main tebak-tebakan, semua keputusan harus berdasarkan hasil monitoring. Soalnya seringkali tebakan kita salah.
-
Jangan lupakan maintenance source code. Proses tuning mungkin saja akan membuat source code menjadi kompleks dan sulit dibaca. Jangan sampai kita mengorbankan kerapian coding demi sedikit peningkatan performance. Lebih baik upgrade hardware daripada mengotori source code.
-
Tahu kapan harus berhenti. Tuning merupakan pekerjaan yang menarik, mirip seperti bermain game. Oleh karena itu penting bagi kita untuk punya tujuan. Begitu tujuan dicapai, segera berhenti. Lebih baik menambah fitur yang memiliki business value daripada terus menerus berkutat dengan performance.
Demikian sekilas tentang tuning. Semoga bermanfaat.
17 Apr 2010
Dari seluruh fase yang ada di project, fase Requirement Development adalah yang paling penting. Bila kita melakukan kegiatan requirement dengan asal-asalan, akibatnya antara lain :
-
aplikasi sudah selesai dibuat, tapi tidak sesuai dengan keinginan user
-
pada fase coding, banyak terjadi delay karena ternyata ada requirement yang belum jelas
-
pada fase coding, banyak pekerjaan harus diulang karena salah memahami requirement
Kenapa saya sebut dengan istilah Requirement Development, bukan Requirement Gathering seperti yang umum dipakai orang? Sebabnya adalah karena requirement yang baik itu tidak didapat dengan mudah. Tidak seperti memungut barang di jalanan (gathering), melainkan harus melalui proses yang iteratif (development). Kita tidak bisa mendapatkan requirement yang baik sekali jalan. Kita harus terus menerus melakukan investigasi, klarifikasi, verifikasi, agar requirement yang didapat benar-benar bagus kualitasnya.
Pada artikel ini, kita akan membahas bagaimana cara membuat requirement yang baik.
Sebelum ke masalah teknis, kita lihat dulu, kenapa kita harus melalui fase requirement? Kenapa tidak langsung coding saja? Kan customer ingin aplikasi jadi, bukan notulensi meeting dan setumpuk dokumen?
Tujuan Requirement
Kita melakukan requirement development karena kita ingin tahu apa yang ingin dibuat. Setelah mengetahui apa yang ingin dibuat, barulah kita bisa:
-
memilih anggota tim yang tepat
-
memperkirakan biaya dan waktu yang dibutuhkan untuk membuatnya
-
memilih arsitektur dan teknologi yang sesuai
Jadi, proses requirement membantu kita untuk melakukan project planning.
Selain itu, proses requirement juga membantu kita mencegah project menjadi molor dan merugi. Kalau kita langsung terjun coding, maka akan banyak waktu terbuang untuk melakukan perubahan. Misalnya, kalau kita sudah coding, ternyata user minta tambahan satu field entry, maka kita terpaksa mengubah tampilan, skema database, format report, dokumentasi user (kalau sudah ada), dan mungkin banyak lagi. Tapi kalau perubahan ini dilakukan pada fase requirement, paling effortnya cuma mengubah dummy dan dokumentasi user story saja.
Requirement juga bisa membantu kita mengendalikan perubahan dalam project, seperti kita akan lihat di bagian selanjutnya.
Setelah kita tahu tujuannya, mari kita ke langkah pertama yang paling menentukan.
Identifikasi Usernya
Segera setelah project dimulai, kita akan segera dihujani jadwal meeting untuk membahas requirement. Nah di sini kita harus jeli. Mendengarkan user itu penting, tapi yang lebih penting lagi adalah menjawab pertanyaan, siapa usernya?
Ada bermacam-macam jenis user, dan ini menentukan informasi apa yang ingin kita dengarkan, dan informasi mana yang kita abaikan.
-
End User. Ini adalah user yang nantinya akan menggunakan aplikasi. Kita harus mendengarkan user ini, terutama dari sisi usability. Apakah aplikasi kita nyaman dipakai, mudah digunakan, indah dilihat, dan sebagainya. Tapi, jangan sekali-kali mengambil keputusan tentang proses bisnis dengan user ini. Jangan juga memutuskan untuk menambah/mengurangi fitur hanya berdasarkan pendapat user ini. Kita membutuhkan user selanjutnya, yaitu :
-
Sponsor atau Client. Ini adalah orang yang akan membayar invoice untuk pembuatan aplikasi. Semua keputusan penting (proses bisnis dan list fitur adalah penting) harus disetujui Client. Dan jangan salah, seringkali pendapat End User tidak sama dengan pendapat Client. Misalnya, Client menginginkan suatu transaksi harus melalui approval supervisor, manager, dan direktur secara berjenjang. Tapi tentunya fitur ini akan memberatkan End User, karena ada banyak proses yang harus dilalui. Nah, tentunya Anda tahu siapa yang harus kita dengarkan. Nah, jadi kapan-kapan melakukan requirement development, cari tahu dulu siapa yang mengotorisasi bilyet giro :D
-
Konsultan Internal. Seringkali di organisasi client, ada seseorang yang cukup senior dari sisi teknis. Bisa jadi dia adalah divisi IT di organisasi client, atau orang luar yang dipercaya oleh client. Apakah orang ini harus kita dengarkan pendapatnya? Tergantung dari seberapa besar pengaruhnya terhadap client. Kita bisa mengetes pengaruhnya dengan membuat satu fitur yang tidak sesuai dengan pendapat konsultan internal ini, dan lihat apa reaksi client. Kalau client setuju dengan kita, berarti pengaruhnya tidak besar, dan pendapat selanjutnya bisa kita diabaikan.
-
Customer. Ada kalanya Client membeli aplikasi kita untuk dijual lagi ke orang lain. Nah orang lain ini disebut Customer. Sukses atau tidaknya project kita banyak ditentukan oleh berapa customer yang bisa didapatkan client. Jadi, penting juga untuk kita mengetahui profil customer (kalau ada). Apa business objective dari customer, sehingga bisa kita akomodasi dengan baik
Baiklah, saya sudah memetakan, si A adalah End User, si B Client, si C konsultan internal, dan si D adalah customernya. Apakah sekarang sudah bisa kita mulai interviewnya? Ok ok .. mari kita suruh Business Analyst (BA) untuk melakukan tugasnya. Oh, tunggu dulu, BA belum direkrut? Bagaimana kualifikasinya?
Kualifikasi Business Analyst
Pertama, BA harus menguasai proses bisnis. Kalau kita ingin membuat aplikasi akunting, BAnya harus mengerti akuntansi. Aturan sederhana dan logis, tapi masih banyak saja perusahaan yang mengirim programmer untuk melakukan requirement development.
Secara umum, BA harus sudah punya pengetahuan dasar dulu sebelum dia ketemu client. Kalau kita kirim programmer, maka dia bukan melakukan requirement development, tapi dia akan belajar bisnis proses ke client. Seperti kita akan lihat, ini pasti akan menimbulkan delay, karena :
Seorang BA harus bisa membedakan mana proses bisnis yang fundamental dan jarang berubah (karenanya boleh dihardcode), mana yang kondisional dan sering berubah (sehingga harus configurable)
Programmer yang belajar bisnis proses ke client tidak akan bisa membedakan ini. Sebagai contoh, mari kita lihat prosedur procurement.
Proses bisnis fundamentalnya adalah, ada pengajuan (purchase request), kemudian dilanjutkan dengan minta quotation ke vendor (request for quotation), memilih vendor, baru melakukan pemesanan (purchase order).
Ini adalah flow fundamental, dan boleh di-hardcode.
Kemudian end user akan bilang, purchase request akan dilakukan oleh masing-masing dept, approval dilakukan manager, dst, dst. Siapa yang mengentri, siapa yang mengapprove, dan pada nilai transaksi berapa dia boleh approve, ini adalah kondisional dan harus bisa dikonfigurasi.
Nah, seorang BA yang baik harus bisa membedakan kedua hal ini.
Coba temani BA anda pada saat sesi interview dengan end user. Kalau dia pernah bilang begini,
Oh, di perusahaan Anda prosesnya begini ya? Biasanya yang umum dilakukan orang adalah seperti ini. Proses Anda kurang optimal karena blablabla. Apakah proses Anda mau berubah, atau aplikasi yang ingin ikut proses Anda dengan konsekuensi ABC?
Nah, kapan-kapan dia minta naik gaji, jangan buru-buru ditolak. Ini BA bagus. Dia menguasai bidangnya, dan tahu best practices.
Banyak perusahaan yang ingin bikin produk dari project tapi tidak kunjung berhasil. Misalnya, ada client minta dibuatkan aplikasi gudang, trus manajemen mikir, “Wah kayaknya ini kalo dibikin jadi produk bakalan prospek”. Tapi ternyata setelah project selesai, aplikasinya tidak applicable di perusahaan lain. Ini salah satu sebabnya adalah BA yang kurang pengalaman sehingga tidak tahu mana fitur yang generik berlaku umum dan mana yang spesifik hanya untuk perusahaan tertentu saja.
Tahu bisnis proses saja masih kurang, BA yang baik juga paham usability. Seperti kita tahu, ada banyak cara untuk mengentri transaksi. Bisa dientri via screen, bisa upload file, bisa via HP, bisa import dari aplikasi lain, dsb. BA yang baik bisa memberikan rekomendasi pada programmer mengenai user experience. Bagaimana urutan screen, penempatan komponen, apakah pilihan tertentu disajikan dengan dropdown, radio, atau lookup.
Kalau BAnya tidak paham usability, aplikasi kita akan benar secara proses bisnis, tapi tidak enak digunakan. Programmer tidak bisa menentukan usability, karena dia tidak tahu bagaimana biasanya end-user menggunakan fitur tertentu.
Ok, BA saya sudah canggih, paham bisnis proses, tau best practices, dan pernah magang sama Jakob Nielsen. Bisa kita mulai interview user?
Interview User
Pada fase ini, biarkan saja BA menjalankan tugasnya. Dia akan berbicara dengan user, dan menanyakan hal-hal berikut:
-
Flow global dari awal sampai akhir. Untuk aplikasi procurement, berarti dari request pembelian, sampai barang diterima.
-
Flow detail untuk masing-masing tahap. Contohnya, bagaimana detail flow proses request pembelian
-
Variasi skenario. Di sini BA akan mengidentifikasi percabangan dari tiap flow. Apa saja variasi skenarionya, perbedaan datanya, role user yang mengaksesnya, kondisi outputnya, dan sebagainya.
Jangan lupa untuk meminta :
-
Contoh report yang diinginkan
-
Sampel data transaksi untuk kita test di internal
-
Rumus atau formula perhitungan
Tergantung clientnya, ada kemungkinan dia akan meminta perjanjian kerahasiaan sebelum mengeluarkan data-data di atas.
Setelah interview, BA pulang ke kantor, dan akan membuat dokumentasi requirement.
Dokumentasi Requirement
Untuk apa kita membuat dokumentasi? Tujuannya adalah
-
Untuk mengidentifikasi kalau ada hal yang kurang jelas, sehingga bisa langsung ditanyakan
-
Sebagai bahan untuk verifikasi dengan user, apakah pemahaman kita sudah sama dengan yang dimaksud user.
-
Sebagai pedoman untuk programmer
-
Untuk mencegah project molor
Lho, bagaimana bisa dokumen requirement mencegah project molor? Ya bisa saja, berikut alasannya
-
Kalau ada kesalahan dan ditemukan pada fase ini, biaya perbaikannya jauh lebih kecil daripada kalau ditemukan pada fase coding. Misalnya ada kesalahan rumus perhitungan. Kalau kesalahan ini ditemukan pada fase requirement, paling biayanya cuma mengedit user story. Tapi kalau ditemukan pada waktu UAT, bisa-bisa butuh 2-3 hari untuk fixingnya. Ini katanya Steve McConnell, bukan bikin-bikinan saya.
-
Setelah requirement disign off, semua perubahan harus melalui change procedure. Ini mencegah project molor karena user terus menerus berubah pikiran. Sekarang maunya A, besok B, lusa ganti lagi.
Lalu, apa saja yang harus didokumentasikan? Daripada panjang lebar, silahkan lihat template User Story ArtiVisi. Di situ sudah kita siapkan form isian apa saja yang harus dicantumkan.
Coba lihat dulu, supaya nyambung dengan pembahasan di bawah.
Lho kenapa ada flow pengetesan? Apa bedanya dengan test scenario?
Sama saja, yang kita maksud flow pengetesan memang adalah test scenario. Lalu apakah wajib dibuat pada fase requirement? Kami sangat menganjurkan untuk membuatnya, dengan alasan sebagai berikut:
-
Dengan memikirkan bagaimana nanti pengetesannya, kualitas user story akan meningkat. BA terpaksa memikirkan step-by-step bagaimana aplikasi akan digunakan, apa inputnya, dan apa outputnya. Dengan memikirkan ini, semua variasi dan kebutuhan input, dan ekspektasi output mau tidak mau akan terpikirkan dan teridentifikasi sejak dini. Ini akan mengurangi requirement yang ambigu, tidak lengkap, atau tidak mungkin diimplementasikan
-
Test scenario yang ditandatangani user merupakan exit strategy bagi vendor. Kalau client sudah setuju dengan skenario testnya, maka vendor cukup membuat aplikasi yang lulus test tersebut. Setelah lulus test, jangan ditambah-tambahi lagi. Ini akan mencegah programmer menambah fitur-fitur menarik namun tidak memiliki business value.
Seperti bisa dilihat pada template, kita mengharuskan adanya screen prototype di dokumen requirement. Screen ini dirancang oleh BA (makanya dia harus paham usability), dan kalau mau, bisa dibuatkan dummy-nya. Dummy bisa dibuat dengan apapun teknologi yang murah dan cepat. Begitu desain screen jadi, seharusnya tidak lebih dari 2 jam waktu yang dibutuhkan untuk membuat dummy-nya, bahkan untuk screen kompleks sekalipun.
Yang harus ada di desain screen adalah :
-
Input field, harus jelas komponennya, apakah text, radio, dsb
-
Contoh isian. Jangan membuat input kosong, buatlah seolah-olah sudah diisi user. Ini akan memudahkan pada saat presentasi
-
Contoh output. Demikian juga dengan output hasil query, report, dsb. Jangan tampilkan tabel kosong. Isilah dengan data statis barang beberapa baris, agar user mempunyai gambaran bagaimana hasil akhirnya
Tidak perlu repot-repot mengimplementasikan dummy ini. Semuanya adalah data statis yang langsung diketik apa adanya.
Dokumen user story dan dummy dipresentasikan ke end user dan direvisi sesuai input. Pada fase ini, end user bebas membuat perubahan apapun yang diinginkan. Perubahan bebas untuk diakomodasi, asal jangan pernah melupakan siapa yang tandatangan otorisasi bilyet giro :D
Sign Off
Setelah semua user story diiterasi dengan end user sampai puas, maka tiba saatnya untuk melakukan feature-freeze. Semua dokumentasi requirement diupdate sehingga sesuai kondisi terakhir, lalu minta approval tertulis dari client. Ingatlah selalu, approval client, bukan end-user, bukan konsultan internal. Ini adalah aktivitas paling critical dan harus dilakukan. Segala usaha proses requirement akan percuma tanpa sign off client.
Change Management
Sebelum sign off, end user bebas mengajukan perubahan apapun. Setelah sign off, semua perubahan harus melalui change procedure. Intinya adalah, perubahan diajukan secara tertulis, diestimasi penambahan durasi dan costnya, lalu diajukan ke manajemen, baik vendor maupun client. Kalau salah satu pihak tidak setuju, maka perubahan tidak akan dijalankan.
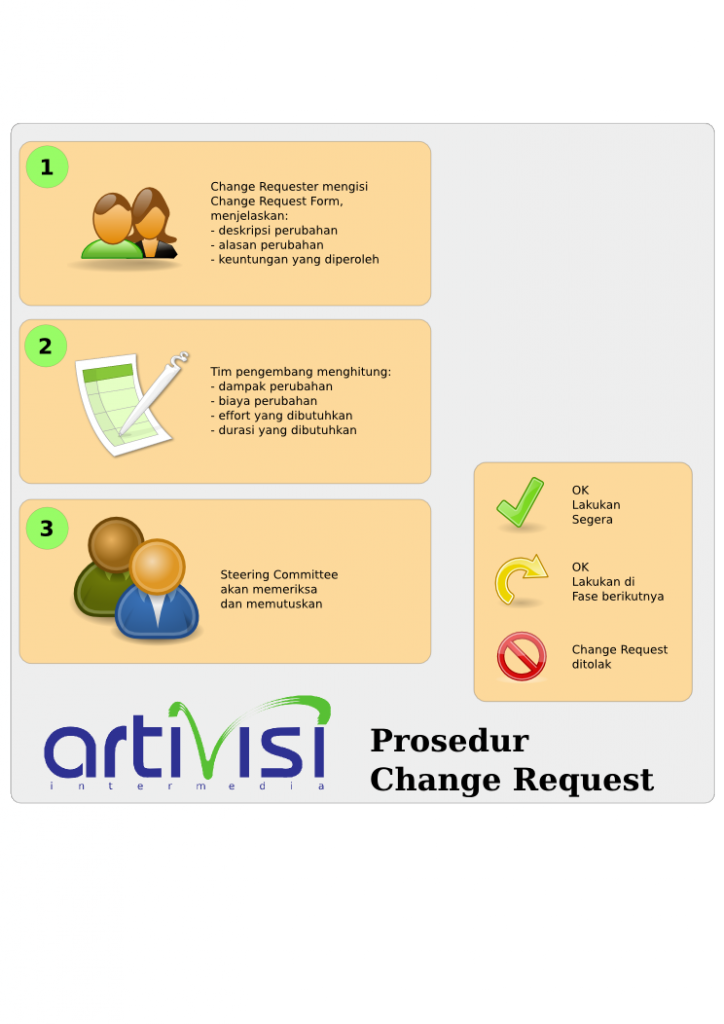
Lebih jelas tentang informasi apa saja yang dibahas di change management, bisa melihat template change request ArtiVisi.
Seperti kita lihat, di sini faktor sign off sangat berperan. Tanpa ada sign off, tidak ada batas kapan user bisa berubah seenaknya, dan kapan tidak boleh.
Kalau change management dijalankan dengan baik, project akan lebih terkontrol. Walaupun ada kemunduran, kedua belah pihak sadar apa sebabnya. Semua perubahan diketahui manajemen, sehingga tidak ada bos yang tiba-tiba muncul dan bilang
Ini project kenapa gak beres-beres?
Kunci sukses change management adalah mulai dari awal, dan perhatikan hal kecil. Kita sebagai vendor sering mengabaikan prosedur ini dengan berbagai alasan, diantaranya
-
Ah perubahannya terlalu kecil, kalo langsung diimplement cuma 5 menit, tapi kalo change procedure bisa 2 hari.
-
Kita tidak mau terlihat birokratis seperti pegawai kelurahan perpanjang KTP
-
Kita berbaik hati pada client, masa perubahan sedikit saja hitung-hitungan banget
Ini merupakan kesalahan besar. Dengan memberlakukan change procedure bahkan untuk hal kecil, kita akan menimbulkan kesadaran di client bahwa kita mengelola project dengan ketat. Dengan demikian, mereka tidak sembarangan meminta perubahan. Client juga akan menyadari bahwa perubahan kecil saja akan berdampak pada keseluruhan project.
Kalau kita memang ingin berbaik hati pada client, silahkan digratiskan. Tapi prosedur tetap dijalankan. Jadi kalo tiba-tiba ada bos client yang tanya seperti di atas, tinggal kita sodori binder berisi daftar change request yang sudah diapprove.
Change procedure juga ada bonusnya, yaitu tidak banyak mengganggu programmer. Estimasi dan approval mostly dilakukan oleh business analyst dan project manager. Dan belum tentu juga client setuju. Kita akan menghemat banyak waktu, konsentrasi, dan pikiran programmer yang tidak perlu memikirkan usulan perubahan yang ternyata tidak disetujui.
Di change request juga ada timing kapan change akan diberlakukan. Untuk menjaga konsentrasi dan ritme tim, PM bisa menggunakan opsi ini untuk menunda change ke iterasi selanjutnya.
Requirement Traceability
Yang satu ini titipan dari CMMI. Di process area Requirement Management, CMMI mengharuskan adanya bidirectional traceability. Artinya, setiap hal di requirement harus bisa ditelusuri dokumen desain mana yang membahasnya, baris kode mana yang mengimplementasikannya, test scenario mana yang memverifikasinya. Demikian juga sebaliknya (makanya disebut bidirectional), setiap baris kode, harus bisa ditelusuri requirement mana yang membutuhkannya.
Ini ide yang bagus. Dengan melaksanakan ini, kita memastikan bahwa effort coding kita benar-benar efisien. Tidak ada effort terbuang percuma untuk fitur-fitur yang tidak perlu. Demikian juga sebaliknya, kita memastikan bahwa semua requirement sudah diimplementasikan dan tidak ada yang ketinggalan.
Walaupun demikian, ide bagus belum tentu realistis di lapangan. Saat ini di ArtiVisi, kita baru bisa merelasikan antara baris kode dengan requirement dengan menggunakan Trac. Tapi tidak untuk dokumen lainnya seperti user manual, test scenario, dsb. Dan itupun tidak bidirectional.
Kalau ingin tahu bagaimana ini diimplementasikan, silahkan lihat aplikasi ini.
Oh iya, kalau kita sudah melakukan semua anjuran di artikel ini, lengkap dengan Requirement Traceability, kita sudah siap untuk diaudit untuk proses area Requirement Management (Maturity Level 2) dan Requirement Development (Maturity Level 3) :D
Demikian penjelasan tentang fase requirement. Semoga bermanfaat.
