29 Jan 2011
Di milis JUG, lagi-lagi ada yang tanya tentang load balancing, failover, dan clustering. Jawabannya masih sama sejak 10 tahun saya berkecimpung di urusan coding-mengcoding. Jadi, baiklah saya tulis di blog saja, supaya next time bisa jadi referensi.
Ini sebetulnya dua hal yang berbeda.
Load balancing ya membagi beban.
Failover ya mencegah single point of failure.
Load Balancing
Load balancer terdiri dari satu balancer dan banyak worker.
Bebannya dibagi2 ke semua worker dengan algoritma yang biasanya bisa dipilih.
Bisa merata (round robin) bisa juga dengan bobot (weighted), misalnya worker X mendapat 2 kali worker Y karena dia specnya lebih tinggi.
Atau bisa juga dynamic, artinya si LB akan mengetes kondisi semua worker, mana yang kira2 sedang idle itu yang dikasi.
Mana yang sedang idle ini nanti ada lagi settingnya, apakah melihat CPU usage pakai SNMP, melihat ping response time, whatever.
Failover minimal harus ada 2 titik.
Kalo kita implement LB aja, point of failure (POF) nya adalah si LB.
Begitu LB nya mati, ya udah semua worker gak bisa diakses.
Untuk mencegah ini, LB nya harus ada 2, satu aktif satu standby (pasif).
Contoh aplikasi load balancer :
- HAProxy
- ldirectord (Ultra Monkey)
- Pound
Contoh aplikasi lain yang bisa jadi load balancer :
- Apache (mod_proxy_balancer)
- Nginx
- lighttpd
- bind (DNS Server)
Failover
Contoh aplikasi failover :
Failover artinya mengatasi kalau ada service yang mati. Ada dua jenis aplikasi untuk menangani failover :
- Network Oriented : keepalived, ucarp
- Cluster Oriented : corosync, heartbeat
Penjelasan lengkapnya bisa dibaca di sini. Namun ringkasnya seperti ini:
Network oriented failover memastikan minimal satu service aktif, dan tidak apa-apa bila ada lebih dari satu service yang aktif. Ini cocok untuk dipasang di load balancer, karena load balancer tidak menyimpan state. Tidak masalah kalau user melihat ada dua LB, kadang diarahkan ke LB-1 dan kadang ke LB-2.
Cluster oriented failover memastikan hanya satu service yang aktif, dan tidak apa-apa bila tidak ada service yang aktif. Ini cocok untuk dipasang di database server, karena kita tidak mau database utama dan cadangan dua-duanya aktif. Bisa-bisa datanya tidak tersimpan dengan benar (split brain). Untuk lebih jelas tentang cara kerja cluster-oriented failover, bisa dibaca di sini.
Nah, mudah2an sampe di sini jelas bahwa load balancing dan failover itu dua hal yang tidak saling terkait (orthogonal) dan biasanya dikombinasikan untuk mendapatkan konfigurasi yang robust dan performant.
Setahu saya konsep2x Clustering diatas berlaku pada saat hit pertama.
Pertanyaan saya.. Bagaimana jika request sudah terlayani tetapi ditengah-tengah proses server tiba2x down.. Apakah proses tersebut langsung di alihkan ke server yang lagi up? Jika iya apakah proses akan di restart dari awal atau server yang sedang up bisa melanjutkan sisa dari proses yang belum dikerjakan di server yang telah down?
Sticky Session
Tidak selalu, tergantung konfigurasinya.
Ada konfigurasi sticky session.
Artinya, pada hit pertama, si user akan diberikan penanda, biasanya berbentuk cookie.
Pada hit berikutnya, LB akan melihat cookienya, dan mengarahkan ke server yang sebelumnya sudah mengurus si user ini.
Ada juga konfigurasi non-sticky.
Artinya tiap hit dianggap hit baru, dan didistribusikan ke semua server sesuai algoritma yang dipilih, round robin, weighted, atau dynamic, sesuai penjelasan di atas.
Mau pilih yang mana? Ya tergantung kemampuan LB nya.
Ada yang bisa 2-2 nya sehingga bisa pilih, dan ada juga yang rada stupid sehingga terpaksa pakai non-sticky.
Istilahnya, LBnya layer berapa? Kalo layer 7 biasanya bisa sticky, kalo layer 4 ya gak bisa.
Lebih jauh tentang urusan layer-layeran ini bisa dibaca di sini dan di sini
Nah, apa impact sticky vs non-sticky?
Ini pengaruhnya ke session data.
Session data adalah data sementara masing-masing user.
Karena sifatnya sementara, maka biasanya tidak disimpan secara persistent di tabel database.
Contoh paling klasik adalah isi shopping cart.
Itu barang belum diorder, tapi sudah dipilih, sehingga biasanya belum disimpan di database.
Kalo pake non-sticky, si user pertama milih barang di server X.
Pada saat dia pilih barang kedua, dilayani server Y.
Karena pilihan pertama ada di server X, ya pas dia pilih barang kedua, cuma tercatat 1 barang padahal harusnya 2.
Ini tidak terjadi kalo kita pakai sticky balancer.
Request kedua dan seterusnya akan diarahkan ke server X lagi.
Jadi, sticky atau non-sticky itu impactnya ke temporary data user, sering disebut dengan istilah session data atau user state.
Nah, setelah jelas apa dampaknya sticky vs non-sticky, mari kita lanjut ke pertanyaan selanjutnya.
Kalau untuk Java EE Application Server apakah untuk pertanyaan saya di atas sudah ada featurenya atau perlu ada tambahan produk lagi untuk bisa sharing informasi terhadap state suatu proses yang dijalankan di satu server sehingga jika server tersebut down proses bisa dilanjutkan di server yang lain tanpa merestart proses?
Session Replication
Mengenai urusan session/state management, ini sangat tergantung merek application server yang digunakan.
Secara umum, settingan standar appserver biasanya simpan data session di memori.
Kalau kita enable cluster, misalnya terdiri dari 4 worker, maka data session ini biasanya akan direplikasi ke satu worker lain.
Pada saat worker utama mati, request berikutnya akan diarahkan ke worker cadangannya, sehingga user gak kehilangan data belanjaan.
Biasanya, satu state itu disimpan ke 2 worker saja, bukan direplikasi ke semua untuk alasan efisiensi bandwidth.
Pada penjelasan di atas banyak sekali saya gunakan kata ‘biasanya’. Ini karena kapabilitas dan konfigurasi masing-masing merek appserver sangat berbeda sehingga sulit untuk menggeneralisir kondisinya.
Lalu bagaimana?
Saya biasanya mengambil pendekatan yang universal, yang jalan di semua appserver, sehingga tidak perlu pusing menghafal appserver apa bisa apa settingnya gimana.
Teknik universalnya sederhana: aplikasi webnya dibuat stateless.
Jangan ada simpan data di memori. Simpan semua di database, atau di distributed cache (misalnya memcached).
Di Java, data yang ada di memori antara lain : session variable, static variable, context variable.
Di PHP, CMIIW cuma session dan global variable aja.
Karena selama ini saya menggunakan teknik ini, jadi saya kurang up to date terhadap appserver apa bisa apa settingnya gimana.
Demikian juga tentang load balancer apa support sticky atau tidak, saya tidak pernah memikirkannya.
Pokoknya simpan state di distributed cache atau database, setelah itu mau pakai appserver Tomcat, Jetty, Glassfish, Weblogic, terserah.
Mau pakai load balancer Apache HTTPD, Nginx, lighty, HAProxy, Pound, Ultramonkey, juga terserah.
Demikian sekilas sharing mengenai load balancing dan clustering. Semoga menjadi cerah.
25 Jan 2011
Posting ini adalah update dari posting tiga tahun yang lalu. Tidak banyak yang berubah dalam stack ini, yang bisa berarti dua hal: pilihan tiga tahun yang lalu sudah tepat atau malas belajar selama 3 tahun ini.
Mudah-mudahan alasannya yang pertama :D
Update : Gradle tidak jadi dipakai, karena kita tidak mau maintain 2 skillset. Maven 2 ternyata stabil dan bekerja sesuai harapan. Hudson terlibat kerusuhan dengan Oracle, akhirnya fork jadi Jenkins.
Presentation Layer
-
Spring MVC
-
SiteMesh
-
Dojo Toolkit
-
ExtJS
-
Spring Security
-
Jasper Report
-
Jackson
Business Layer
-
Spring Framework
-
Hibernate
Library lain yang sering digunakan
-
Logback
-
Joda Time
-
Velocity
-
JPos
Infrastruktur
-
Version Control : Git + Gitosis
-
Testing Tools : JUnit, DBUnit, JMeter, Sonar
-
Issue Tracker : Redmine
-
Build Tools : Gradle, Maven
-
Continuous Integration : Hudson Jenkins
-
OS Programmer : Ubuntu Desktop
-
OS Server : Ubuntu Server, Debian
Deployment Target
-
Database Server : MySQL, Oracle
-
Application Server : Tomcat, Glassfish
Praktis perubahan yang terjadi hanyalah dari Subversion ganti menjadi Git.
Nah, bagaimana menurut Anda? Pilihan tepat atau malas belajar?
11 Jan 2011
Skenario : selama ini kita coding di laptop sendiri saja. Kemudian ada kebutuhan untuk kolaborasi dengan orang lain melalui Git. Bagaimana caranya? Baiklah mari kita bahas di artikel ini.
Inisialisasi Repository Git
Pertama, kita inisialisasi dulu repository Git. Masuk ke dalam folder project dan ketikkan
Git akan membuat repository kosong di dalam folder project, ditandai dengan adanya folder baru bernama .git
Selanjutnya, kita akan memasukkan semua file dan folder project kita ke dalam repository. Yang harus dimasukkan adalah file source code, baik itu Java, HTML, XML, dan sebagainya. Yang tidak perlu dimasukkan adalah file hasil kompilasi atau hasil generate. Kita perlu mendaftarkan file yang tidak ingin disimpan dalam file konfigurasi yang bernama .gitignore
File ini harus kita buat sendiri menggunakan text editor. Berikut contoh isi filenya, bila kita coding menggunakan Eclipse atau Netbeans
[gist id=773975]
Setelah kita setting ignore file, berikutnya kita masukkan semua file dan folder ke dalam antrian.
Kemudian, simpan ke repository
git commit -m "commit pertama project XXX"
Project sudah tersimpan di repository Git di komputer lokal kita. Mari kita upload ke server, atau dikenal dengan istilah push.
Share Repository
Kita memerlukan server di mana kita memiliki ijin akses untuk melakukan push. Cara memperoleh ijin akses tidak dibahas pada artikel ini. Silahkan buat account di Github atau Gitorious. Bila ingin push ke repository perusahaan, minta informasinya pada admin Anda.
Setelah kita mendapatkan URL server yang bisa kita gunakan, daftarkan sebagai remote. Berikut perintahnya.
git remote add <namaremote> <URL>
Contohnya seperti ini
git remote add github git@github.com:endymuhardin/project-terbaru-saya.git
Pastikan remotenya sudah terdaftar dengan perintah berikut
Terakhir, mari kita push dengan perintah berikut
git push <namaremote> <namabranch>
Contohnya
Hore, project kita sudah naik ke server. Kita tinggal share URL tersebut ke rekan kerja kita.
08 Jan 2011
Gist adalah fitur yang disediakan oleh Github. Fungsi dasarnya mirip dengan pastebin, yaitu kita bisa paste text di sana, dan disharing dengan orang lain. Keunggulan Gist adalah dia sudah memiliki kemampuan version control dengan Git. Sehingga kita bisa fork, clone, modifikasi, dan push lagi ke repo utama dengan seluruh history tersimpan di sana.
Untuk bisa menggunakan Gist, kita harus memiliki account Github dulu. Setelah itu, kita bisa buat gist di sini.
Cara membuatnya tidak sulit. Cukup entri nama file, keterangan, dan isi text yang mau dishare.
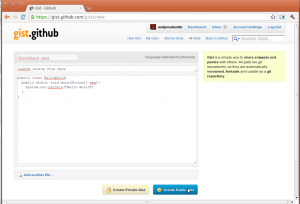
Setelah itu, tekan Create Public Gist. Gist kita akan siap digunakan.
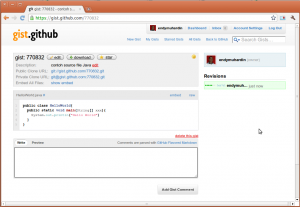
Gist yang sudah dibuat bisa dipasang di blog. Caranya, klik tombol embed.
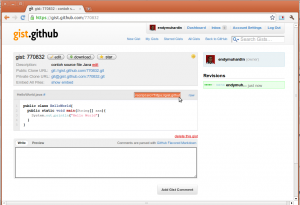
Nanti akan muncul textfield berisi tag HTML untuk dipasang di blog, kira-kira seperti ini tagnya:
<script src="https://gist.github.com/770832.js?file=HelloWorld.java"></script>
Tag ini bisa langsung dipasang di blog kita. Hasilnya seperti di bawah ini.
Kelemahan cara ini adalah dia membutuhkan javascript, dan isi filenya tidak terindeks oleh spider. Untuk mengatasinya, kita gunakan plugin wordpress ini.
Setelah digunakan, kita cukup memasang tag khusus seperti dijelaskan di websitenya. Ini contoh hasilnya
[gist id=770832]
Sekilas tidak terlihat bedanya antara pakai plugin dan tidak. Tapi coba lihat source halaman ini, klik kanan kemudian View Source. Yang menggunakan plugin, source codenya benar-benar ada tulisannya. Sedangkan yang pakai tag script tidak ada source code hello worldnya.
Nah, kalau sudah pakai ini, tidak perlu bingung lagi mewarnai source code di blog. Kalau mau revisi, tinggal edit aja di Github, dan otomatis di blog langsung terupdate.
07 Jan 2011
Setelah kemarin kita bahas migrasi di sisi server, sekarang kita bahas instalasi di client. Kenapa yang dijelaskan hanya Windows, sedangkan Linux tidak? Well, ini karena di Linux instalasinya begitu mudah sehingga terlalu pendek kalau ingin dijadikan satu posting sendiri.
Gak percaya? Ini caranya install di Ubuntu. Buka command prompt, dan ketik
sudo apt-get install git-core git-svn git-gui gitk
Sedikit konfigurasi standar.
git config --global user.name "Endy Muhardin"
git config --global user.email "endy.muhardin@geemail.com"
git config --global color.ui "true"
Kemudian, bila kita belum punya public key, silahkan bikin seperti tutorial di sini.
Dan selesailah sudah. Seperti saya bilang sebelumnya, singkat dan sama sekali gak seru. Gak ada screenshotnya :D
Nah, mari kita bahas instalasi di Windows.
Pertama, unduh Git dari websitenya. Pastikan kita mengambil yang sesuai dengan arsitektur komputer kita (32 bit atau 64 bit).
Setelah diunduh, tentu kita jalankan. Berikut screenshot next-next seperti biasa.

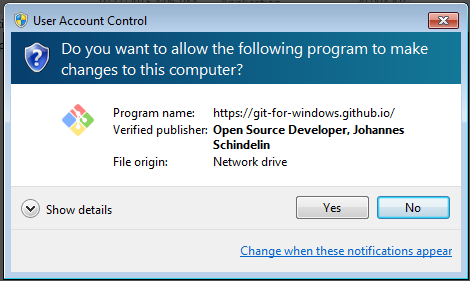
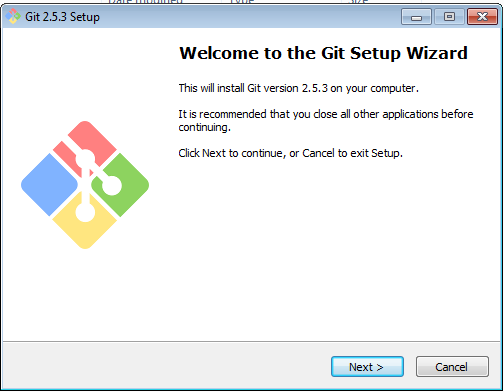

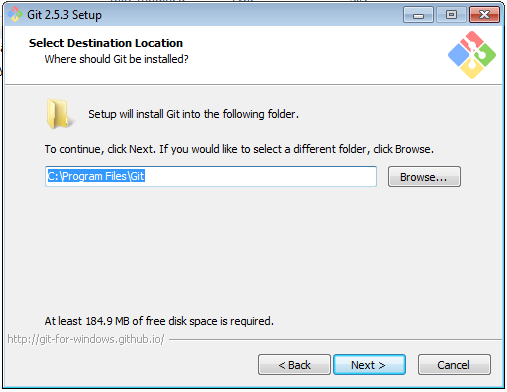


Perhatikan, untuk langkah selanjutnya, kita perlu mengganti opsi default menjadi pilihan yang kedua.

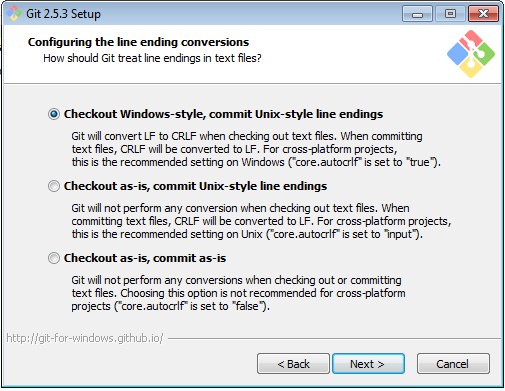
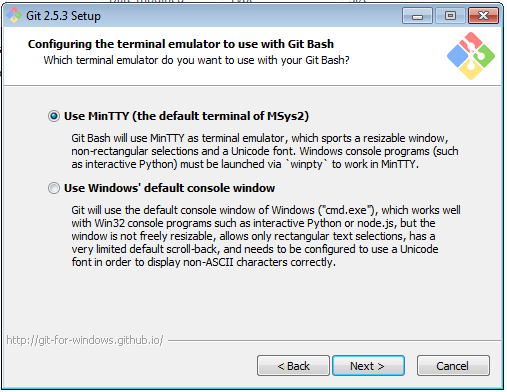



Sampai di sini, instalasi Git sebetulnya sudah selesai. Tapi kita perlu membuat pasangan public dan private key supaya bisa mengakses Github, Bitbucket, atau provider lain melalui protokol SSH. Dengan menggunakan protokol SSH, kita tidak perlu mengetik username/password setiap melakukan sinkronisasi dengan remote repository.
Membuat Key Pair
Pertama, kita jalankan dulu Git Bash. Ini akan membuka command prompt khusus yang disediakan Git.

Selanjutnya, jalankan perintah ssh-keygen. Kita akan ditanyai nama file yang akan dibuat. Ikuti saja defaultnya, yaitu id_rsa untuk private key, dan id_rsa.pub untuk public key.
Kita juga akan dimintai password untuk membuka private key. Tekan Enter bila tidak mau pakai password.

Selanjutnya, kita akan menemui kedua file private dan public key di folder C:\Users\namauser\.ssh seperti ini.

Kedua file bisa dibuka dengan text editor. Yang perlu kita buka hanyalah public key saja.

Isi public key ini nantinya akan kita pasang di Github
Clone dari Github
Untuk bisa clone dari github, pertama kali kita harus punya account Github. Silahkan daftar dulu.
Setelah punya account, login, dan kita akan melihat dashboard.
Klik account setting, dan masuk ke menu SSH Public Keys
Pastekan public key yang sudah kita generate pada langkah sebelumnya. Setelah diadd, public key kita akan terdaftar. Kita boleh pasang public key banyak-banyak, karena biasanya satu public key mencerminkan satu komputer. Bisa saja kita punya PC dan juga Laptop.
Setting Public Key di Bitbucket
Selain Github, provider lain yang juga populer adalah Bitbucket. Untuk mendaftarkan public key di Bitbucket, kita bisa akses menu di kanan atas, yang ada gambar avatar kita.

Pilih Bitbucket Settings, kita akan mendapatkan halaman Settings

Klik SSH Keys di kiri bawah. Kita akan mendapati halaman untuk menambah SSH Keys.
Klik Add Key untuk menambah public key SSH. Selanjutnya, copy dan paste isi public key kita ke kotak yang disediakan.
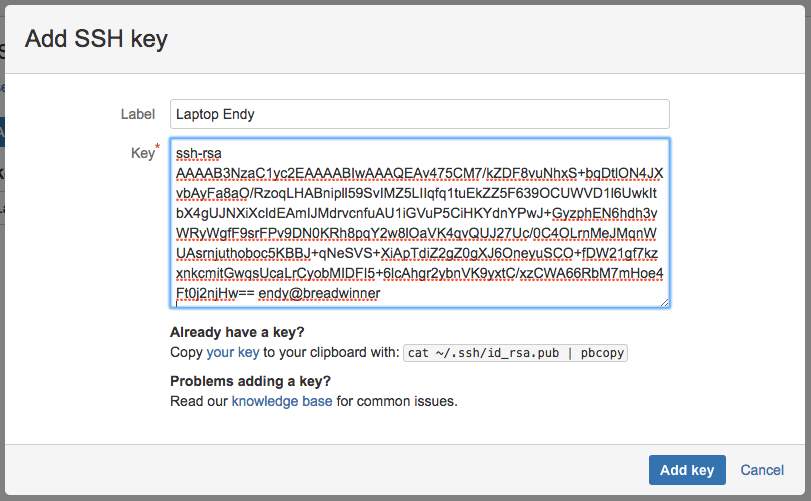
Klik Save, dan public key kita sudah terdaftar

Kita juga akan mendapatkan notifikasi lewat email bahwa ada SSH key baru yang didaftarkan
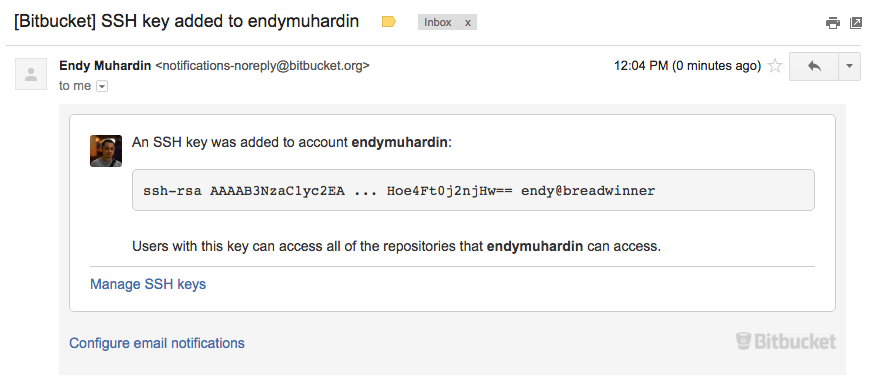
Mengunduh Isi Repository
Setelah public key didaftarkan, selanjutnya kita lihat repository yang kita punya.
Kalau belum punya repository, Anda bisa fork repository belajarGit punya saya, sehingga nanti Anda punya repo belajarGit sendiri.
Perintahnya adalah sebagai berikut (jalankan dari command line)
git clone git@github.com:endymuhardin/belajarGit.git
Sekarang repository sudah ada di local, dan siap digunakan. Bagaimana cara menggunakannya, stay tuned. Akan dibahas di posting berikutnya.
