
Membuat Aplikasi yang Cluster Ready
18 Apr 2017Beberapa tahun yang lalu, kita sudah membahas tentang konsep clustering aplikasi. Ada beberapa konsep dan istilah penting di sana seperti:
- Dua jenis aplikasi failover
- Session Affinity atau Sticky/Non-Sticky Session
Kita tidak akan bahas lagi tentang istilah tersebut, silahkan baca artikel terdahulu untuk memahaminya. Pada artikel kali ini, kita akan membahas tentang implementasi konsep tersebut dalam aplikasi kita, sehingga diharapkan pembaca sudah paham artinya.
Memasang aplikasi yang sama di beberapa mesin (baik fisik ataupun virtual) disebut dengan istilah clustering atau replication. Kita akan menggunakan istilah replikasi pada artikel ini.
Contoh kode program dibuat menggunakan Java. Akan tetapi, prinsip-prinsipnya bisa juga diterapkan pada aplikasi yang menggunakan bahasa pemrograman lain.
Clustering bukan sesuatu yang sederhana. Baik secara konfigurasi, pembuatan aplikasi, dan secara biaya. Bandingkan deployment kita yang biasanya seperti ini
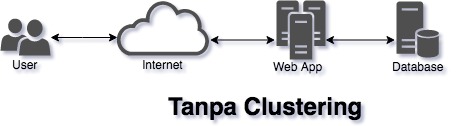
Menjadi seperti ini
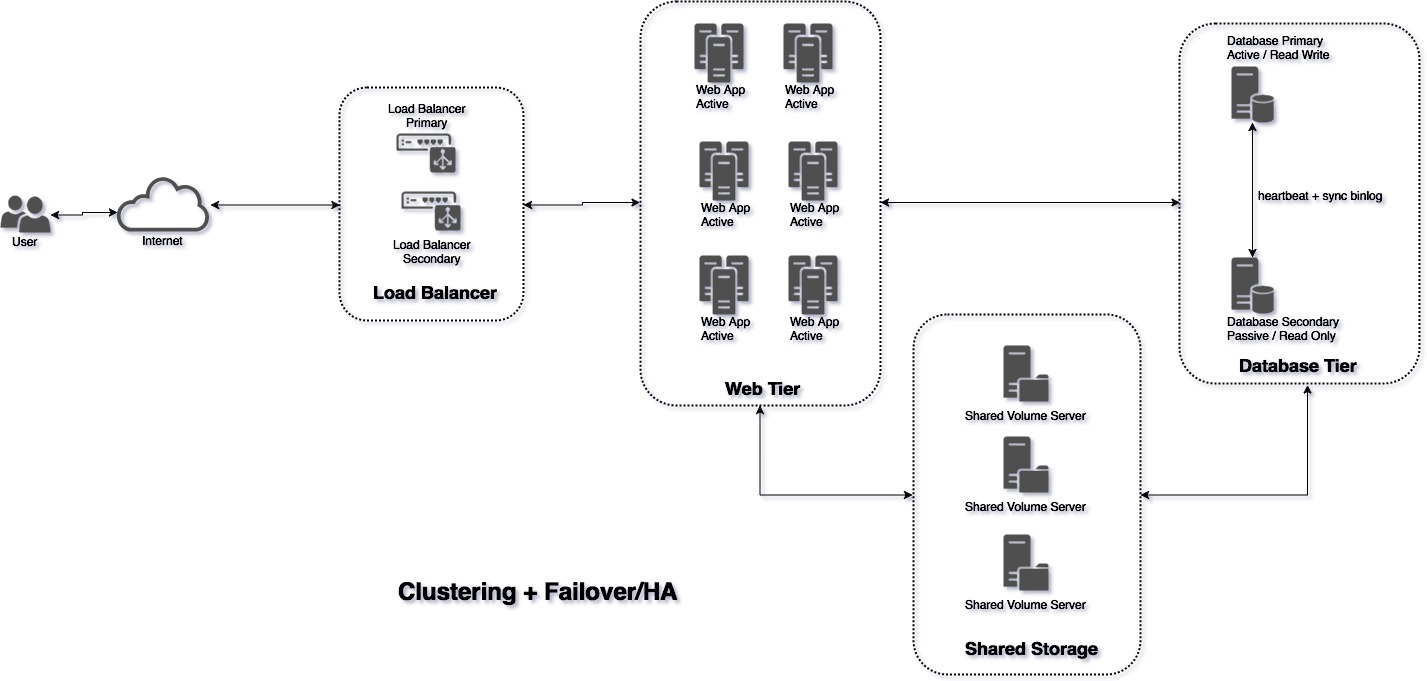
Umumnya, orang melakukan replikasi atau clustering karena dua alasan:
- Failover : bila satu server mati, ada server cadangan yang siap mengambil alih
- Scalability : bila satu server sudah tidak kuat menangani request yang banyak, upgrade hardware (scale up) sudah mentok, maka kita bisa menambah server (scale out)
Buat kita programmer, tidak masalah apapun alasannya. Tetap saja kita harus melakukan antisipasi agar aplikasi yang kita buat bisa dicluster dengan baik. Secara garis besar, ada dua hal yang harus kita perhatikan:
- data di memory : misalnya instance variable, session variable, dan static variable
- data di disk : misalnya file hasil upload, file log, file report hasil generate, file temporary, dan sebagainya
Pada saat dilakukan replikasi, akan ada banyak instance aplikasi yang berjalan di banyak mesin. Request yang datang bisa diarahkan ke mesin mana saja. Request pertama untuk user tertentu (misalnya pilih barang), belum tentu diarahkan ke mesin yang sama dengan request selanjutnya (misalnya bayar). Dengan demikian, kita tidak bisa menyimpan data pilihan barang di request pertama dalam memori mesin pertama. Karena pada request berikutnya, bisa jadi ditangani oleh mesin lain yang berbeda. Bila datanya disimpan di memori mesin pertama, maka pada waktu request bayar ditangani mesin kedua, dia tidak punya data pilihan produknya.
Demikian juga dengan penyimpanan data di disk. Bila request upload file dihandle dengan cara menulis langsung ke local disk, request berikutnya bisa jadi ditangani mesin lain yang tidak memiliki file tersebut di local disknya.
Seperti kita lihat pada gambar di atas, kita punya enam instance aplikasi web. Berarti ada kemungkinan satu banding enam request kedua akan ditangani server yang sama dengan request pertama. Oleh karena itu, aplikasi web kita harus menyimpan data (baik memori maupun disk) di tempat yang bisa diakses keenam instance tersebut.
Data di Memory
Untuk masalah data di memory, solusi yang biasa dipakai adalah memindahkan penyimpanan data ke database server. Bisa menggunakan database relasional seperti MySQL atau PostgreSQL, bisa juga menggunakan database NoSQL seperti memcached, redis, atau lainnya.
Bila kita menggunakan Spring Framework, memindahkan session variables ke database server bisa dilakukan dengan mudah. Caranya :
- tambahkan dependensi
spring-session-jdbc - tambahkan anotasi
@EnableJdbcHttpSession - buat skema tabel buat menyimpan data session
Berikut dependensi di pom.xml
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-jdbc</artifactId>
</dependency>
Anotasi @EnableJdbcHttpSession bisa kita pasang di main class
@SpringBootApplication
@EnableJdbcHttpSession
public class BelajarCiApplication {
public static void main(String[] args) {
SpringApplication.run(BelajarCiApplication.class, args);
}
}
Bila kita menggunakan MySQL, skema databasenya sebagai berikut
CREATE TABLE SPRING_SESSION (
SESSION_ID CHAR(36),
CREATION_TIME BIGINT NOT NULL,
LAST_ACCESS_TIME BIGINT NOT NULL,
MAX_INACTIVE_INTERVAL INT NOT NULL,
PRINCIPAL_NAME VARCHAR(100),
CONSTRAINT SPRING_SESSION_PK PRIMARY KEY (SESSION_ID)
) ENGINE=InnoDB;
CREATE INDEX SPRING_SESSION_IX1 ON SPRING_SESSION (LAST_ACCESS_TIME);
CREATE TABLE SPRING_SESSION_ATTRIBUTES (
SESSION_ID CHAR(36),
ATTRIBUTE_NAME VARCHAR(200),
ATTRIBUTE_BYTES BLOB,
CONSTRAINT SPRING_SESSION_ATTRIBUTES_PK PRIMARY KEY (SESSION_ID, ATTRIBUTE_NAME),
CONSTRAINT SPRING_SESSION_ATTRIBUTES_FK FOREIGN KEY (SESSION_ID) REFERENCES SPRING_SESSION(SESSION_ID) ON DELETE CASCADE
) ENGINE=InnoDB;
CREATE INDEX SPRING_SESSION_ATTRIBUTES_IX1 ON SPRING_SESSION_ATTRIBUTES (SESSION_ID);
Sedangkan untuk PostgreSQL, skemanya seperti ini
CREATE TABLE SPRING_SESSION (
SESSION_ID CHAR(36),
CREATION_TIME BIGINT NOT NULL,
LAST_ACCESS_TIME BIGINT NOT NULL,
MAX_INACTIVE_INTERVAL INT NOT NULL,
PRINCIPAL_NAME VARCHAR(100),
CONSTRAINT SPRING_SESSION_PK PRIMARY KEY (SESSION_ID)
);
CREATE INDEX SPRING_SESSION_IX1 ON SPRING_SESSION (LAST_ACCESS_TIME);
CREATE TABLE SPRING_SESSION_ATTRIBUTES (
SESSION_ID CHAR(36),
ATTRIBUTE_NAME VARCHAR(200),
ATTRIBUTE_BYTES BYTEA,
CONSTRAINT SPRING_SESSION_ATTRIBUTES_PK PRIMARY KEY (SESSION_ID, ATTRIBUTE_NAME),
CONSTRAINT SPRING_SESSION_ATTRIBUTES_FK FOREIGN KEY (SESSION_ID) REFERENCES SPRING_SESSION(SESSION_ID) ON DELETE CASCADE
);
CREATE INDEX SPRING_SESSION_ATTRIBUTES_IX1 ON SPRING_SESSION_ATTRIBUTES (SESSION_ID);
Selain menambah dependensi, anotasi @EnableJdbcHttpSession, dan menambah tabel di database, tidak ada perubahan lain yang perlu kita lakukan di kode program kita.
Data di Disk
Agar aplikasi web kita bisa direplikasi, pada prinsipnya kita harus sediakan tempat penyimpanan yang bisa diakses semua instance. Ada beberapa alternatif di sini:
- menggunakan shared filesystem
- menggunakan storage service
Solusi shared filesystem bisa diimplementasikan dengan berbagai produk, diantaranya:
- GlusterFS
- Ceph
- NFS
- OCFS2
Untuk lebih detail mengenai implementasinya bisa dibaca di sini.
Solusi filesystem ini tidak mengharuskan kita mengubah kode program. Aplikasi kita melihat shared filesystem ini sebagai folder biasa dalam sistem operasi. Kita bisa baca tulis file seperti biasa. Nanti filesystemnya yang akan mengurus replikasinya ke berbagai node. Kita hanya perlu melakukan mounting shared folder tersebut ke folder di masing-masing node.
Selain solusi shared filesystem, kita juga bisa menggunakan aplikasi terpisah yang bertugas menjadi file server. Setiap mau menulis file, kita upload filenya ke file server. Demikian juga kalau kita ingin melihat daftar file atau mengambil isi file, kita bisa mengakses file server tersebut. Protokol yang umum digunakan jaman sekarang adalah HTTP.
Kita bisa instal sendiri file servernya, atau kita bisa gunakan layanan cloud yang sekarang banyak tersedia di internet. Ada Amazon S3, Dropbox, Google Cloud Storage, dan lainnya. Sebagai contoh, berikut implementasi menulis file ke layanan Google Cloud Storage
private static final String BUCKET_NAME = "belajar-ci";
private Storage storage = StorageOptions.getDefaultInstance().getService();
public void simpan(String nama, InputStream contentStream) {
storage.create(BlobInfo.newBuilder(BUCKET_NAME, nama).build(),
contentStream);
}
Untuk melihat daftar file, berikut kode programnya
public List<Map<String, Object>> daftarFile() {
List<Map<String, Object>> hasil = new ArrayList<>();
Page<Blob> daftarFile = storage.list(BUCKET_NAME, Storage.BlobListOption.currentDirectory());
daftarFile.getValues().forEach( blob -> {
Map<String, Object> fileInfo = new TreeMap<>();
fileInfo.put("nama", blob.getName());
fileInfo.put("ukuran", blob.getSize());
hasil.add(fileInfo);
});
return hasil;
}
Dan untuk mengambil isi file, kode programnya seperti ini:
public InputStream ambil(String nama) {
return new ByteArrayInputStream(
storage.readAllBytes(BlobId.of(BUCKET_NAME, nama)));
}
Jangan lupa untuk memasang dependensi di pom.xml
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-storage</artifactId>
<version>0.11.0-beta</version>
</dependency>
Agar aplikasi kita bisa berjalan dengan baik, kita perlu membuatkan dulu bucketnya di Google Cloud Storage. Kita membutuhkan aplikasi command line gsutil yang ada dalam paket Google Cloud SDK. Cara setupnya sudah kita bahas pada artikel terdahulu.
Pertama, kita buat dulu bucketnya
gsutil mb gs://belajar-ci
Setelah itu, kita bisa melihat bucket apa saja yang sudah ada dengan perintah berikut
gsutil ls
Kita akan mendapatkan bucket kita sudah terdaftar
gs://belajar-ci/
Menjalankan Replikasi
Dulu, membuat instalasi clustering dan failover seperti gambar di atas relatif sulit. Kita harus instal semua node satu persatu, memasang alamat IP, mengatur subnet, menghubungkan antar node dengan keepalived atau heartbeat, konfigurasi load balancer dengan HAProxy atau Nginx, dan banyak urusan lainnya. Sekarang, dengan teknologi cloud, mau replikasi berapa node pun bisa dilakukan dengan satu baris perintah.

Kubernetes
Berikut perintahnya bila kita deploy ke Kubernetes. Pertama kita lihat dulu kondisi awalnya
kubectl get all -l app=belajar-ci
Berikut outputnya
NAME READY STATUS RESTARTS AGE
po/belajar-ci-app-4282971413-j4x55 1/1 Running 1 8m
po/belajar-ci-db-588835421-xh32q 1/1 Running 0 8m
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/belajar-ci-app-service 10.47.254.61 <pending> 80:30446/TCP 8m
svc/belajar-ci-db-service 10.47.243.72 <none> 3306/TCP 8m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/belajar-ci-app 1 1 1 1 8m
deploy/belajar-ci-db 1 1 1 1 8m
NAME DESIRED CURRENT READY AGE
rs/belajar-ci-app-4282971413 1 1 1 8m
rs/belajar-ci-db-588835421 1 1 1 8m
Kita lihat bahwa saat ini aplikasi kita terdiri dari satu instance web dan satu instance database. Mari kita replikasi aplikasi webnya menjadi … hmmmm …. kita coba saja 27 node :D
kubectl scale --replicas=27 deploy/belajar-ci-app
Beberapa detik kemudian, keluar outputnya
deployment "belajar-ci-app" scaled
Setelah selesai, kita lihat lagi output dari kubectl get all -l app=belajar-ci
NAME READY STATUS RESTARTS AGE
po/belajar-ci-app-4282971413-06wnz 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-19364 1/1 Running 0 1m
po/belajar-ci-app-4282971413-1vd2g 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-2m76g 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-2mvr6 1/1 Running 0 1m
po/belajar-ci-app-4282971413-36sqq 1/1 Running 0 1m
po/belajar-ci-app-4282971413-3c2gc 1/1 Running 0 1m
po/belajar-ci-app-4282971413-5xn38 1/1 Running 0 1m
po/belajar-ci-app-4282971413-70mhg 1/1 Running 0 1m
po/belajar-ci-app-4282971413-9j7m7 1/1 Running 0 1m
po/belajar-ci-app-4282971413-bzxwz 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-cvbkg 1/1 Running 0 1m
po/belajar-ci-app-4282971413-dr9w0 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-flffm 1/1 Running 0 1m
po/belajar-ci-app-4282971413-fqmr9 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-j4x55 1/1 Running 1 12m
po/belajar-ci-app-4282971413-k8597 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-lgj07 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-ltsvd 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-md16l 1/1 Running 0 1m
po/belajar-ci-app-4282971413-mjfj7 1/1 Running 0 1m
po/belajar-ci-app-4282971413-s4vn1 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-sfgwt 0/1 Pending 0 1m
po/belajar-ci-app-4282971413-wgbg7 1/1 Running 0 1m
po/belajar-ci-app-4282971413-wr6vf 1/1 Running 0 1m
po/belajar-ci-app-4282971413-wxpg5 1/1 Running 0 1m
po/belajar-ci-app-4282971413-z3jqj 1/1 Running 0 1m
po/belajar-ci-db-588835421-xh32q 1/1 Running 0 12m
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/belajar-ci-app-service 10.47.254.61 <pending> 80:30446/TCP 12m
svc/belajar-ci-db-service 10.47.243.72 <none> 3306/TCP 12m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/belajar-ci-app 27 27 27 16 12m
deploy/belajar-ci-db 1 1 1 1 12m
NAME DESIRED CURRENT READY AGE
rs/belajar-ci-app-4282971413 27 27 16 12m
rs/belajar-ci-db-588835421 1 1 1 12m
Aplikasi web kita sudah punya 27 instance, tapi beberapa diantaranya masih dalam proses inisialisasi. Kita bisa jalankan perintah tersebut beberapa menit kemudian untuk melihat hasilnya. Tentunya jumlah replikasi ini harus disesuaikan dengan kemampuan dan jumlah node yang ada ya. Jangan nanti mau replikasi 100 instance, tapi cuma sedia 2 atau 3 VM ukuran small saja :P
Heroku
Di Heroku juga sama, kita bisa replikasi dengan satu perintah:
heroku ps:scale web=27
Pivotal Cloud Foundry
Demikian juga di Pivotal Cloud Foundry, untuk mereplikasi menjadi 27 instance, jalankan perintah berikut
cf scale belajar-ci -i 27
Mengetes Replikasi
Untuk melihat apakah aplikasi kita sudah jalan, kita bisa akses aplikasinya. Saya sudah membuatkan halaman depan yang menampilkan hostname yang sedang melayani request.
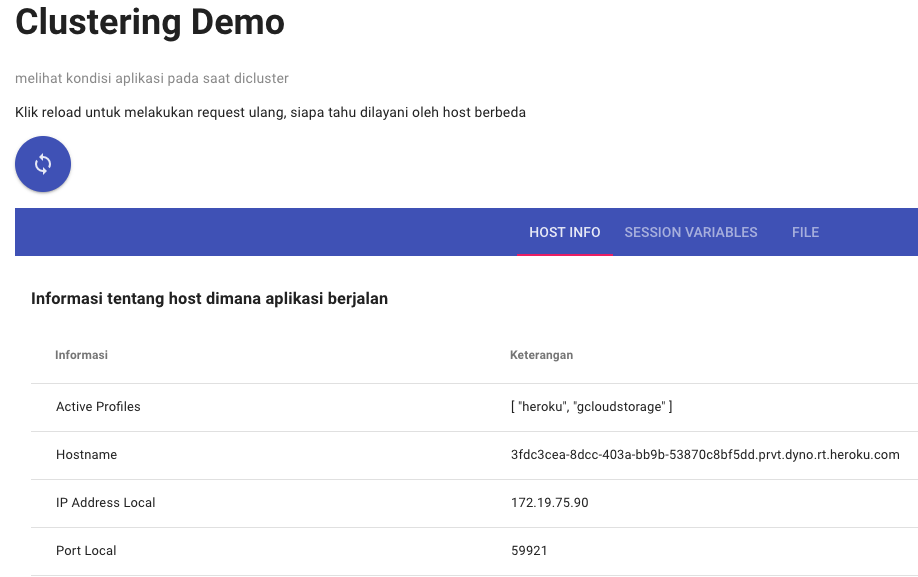
Klik tombol reload beberapa kali. Kita akan melihat bahwa isi Hostname dan IP Address Local akan berganti-ganti sesuai node yang melayani request. Kita juga bisa coba mengisi Session Variable dan Upload File untuk memastikan bahwa datanya tetap ada walaupun kita dilayani node yang berganti-ganti.
Penutup
Di tahun 2017 ini replication dan failover sudah sangat mudah. Dengan satu kali perintah saja, kita sudah bisa menambah instance aplikasi. Bahkan berbagai penyedia layanan cloud sudah menyediakan fasilitas autoscaling, yaitu secara otomatis menambah instance pada saat aplikasi kita mencapai pemakaian CPU/RAM tertentu. Informasi lebih lanjut mengenai autoscaling dapat dibaca di masing-masing penyedia:
Pastikan kita membuat aplikasi yang sudah siap direplikasi dengan memperhatikan hal-hal yang kita bahas di atas. Dengan demikian, kita bisa memanfaatkan kecanggihan teknologi cloud secara maksimal.
Seperti biasa, kode program bisa diakses di Github
Semoga bermanfaat …